

Authors:
(1) Maria Rigaki, Faculty of Electrical Engineering, Czech Technical University in Prague, Czech Republic and [email protected];
(2) Sebastian Garcia, Faculty of Electrical Engineering, Czech Technical University in Prague, Czech Republic and [email protected].
Table of Links
Conclusion, Acknowledgments, and References
Appendix
A. Hyper-parameter Tuning
The search space for the PPO hyper-parameters:
– gamma: 0.01 - 0.75
– max grad norm: 0.3 - 5.0
– learning rate: 0.001 - 0.1
– activation function: ReLU or Tanh
– neural network size: small or medium
Selected parameters: gamma=0.854, learning rate=0.00138, max grad norm=0.4284,
activation function=Tanh, small network size (2 layers with 64 units each).
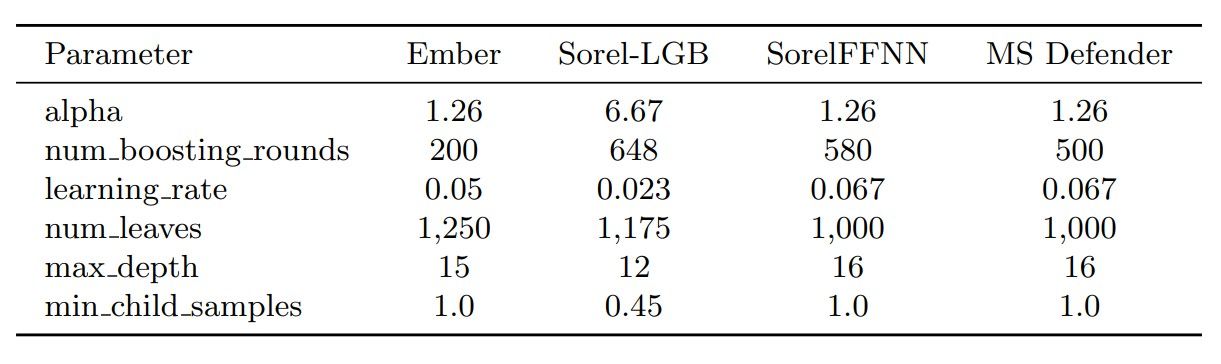
The search space for the LGB surrogate training hyper-parameters:
– alpha: 1 - 1,000
– num boosting rounds: 100-2,000
– learning rate: 0.001 - 0.1
– num leaves: 128 - 2,048
– max depth: 5 - 16
– min child samples: 5 - 100
– feature fraction: 0.4 - 1.0
Table 4. Hyper-parameter settings for the training of each LGB surrogate
This paper is available on arxiv under CC BY-NC-SA 4.0 DEED license.