
Authors:
(1) Muzhaffar Hazman, University of Galway, Ireland;
(2) Susan McKeever, Technological University Dublin, Ireland;
(3) Josephine Griffith, University of Galway, Ireland.
Table of Links
Conclusion, Acknowledgments, and References
A Hyperparameters and Settings
E Contingency Table: Baseline vs. Text-STILT
E Contingency Table: Baseline vs. Text-STILT
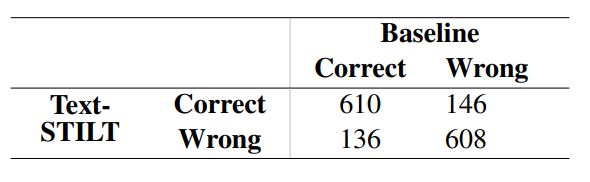
Table 8 shows the contingency table – as one would prepare for a McNemar’s Test between two classifiers (McNemar, 1947) – between the model trained with Text-STILT on 60% Memes and Baseline trained on 100% Memes available which had the most similar performance. While the two models performed similarly in terms of Weighted F1- scores, Text-STILT correctly classified a notable number of memes that Baseline did not and vice versa. Examples of such memes are discussed in Section 4.1. Furthermore, approximately 40% of memes in the testing set were incorrectly classified by both models. This suggests that these memes convey sentiment in a way that cannot be reliably predicted by either approach.
This paper is available on arxiv under CC 4.0 license.