
This paper is available on arxiv under CC BY-NC-SA 4.0 DEED license.
Authors:
(1) Cristina España-Bonet, DFKI GmbH, Saarland Informatics Campus.
Table of Links
- Abstract and Intro
- Corpora Compilation
- Political Stance Classification
- Summary and Conclusions
- Limitations and Ethics Statement
- Acknowledgments and References
- A. Newspapers in OSCAR 22.01
- B. Topics
- C. Distribution of Topics per Newspaper
- D. Subjects for the ChatGPT and Bard Article Generation
- E. Stance Classification at Article Level
- F. Training Details
3. Political Stance Classification
The Network. **We finetune XLM-RoBERTa large (Conneau et al., 2020), a multilingual transformer-**based masked LM trained on 100 languages including the 4 we consider. The details of the network and the hyperparameter exploration per model are reported in Appendix F.
The Models. We train 4 models: 3 monolingual finetunings with the English, German and Spanish data, plus a multilingual one with the shuffled concatenation of the data. All models are based on multilingual embeddings (RoBERTa) finetuned either monolingually or multilingually. Notice that we do not train any model for Catalan. With this, we want to compare the performance of mono- and multilingual finetunings and explore the possibility of using multilingual models for zero-shot language transfer.
Coarse Classification with Newspaper Articles. Table 2 summarises the results. All the models achieve more than 95% accuracy on the validation set which is extracted from the same distribution as the training data. In order to see how the models behave with unseen data, we calculate the percentage of articles that are classified as Left (L) and Right (R) in the test newspapers of Table 1. We perform bootstrap resampling of the test sets with 1000 bootstraps to obtain confidence intervals at 95% level. We do not expect all the articles of a newspaper leaning towards the Left to show clear characteristics of the Left, but given that there is no neutral class, we expect the majority of them to be classified as Left. A good result is not necessarily 100%–0%, as this would not be realistic either. We consider that a newspaper has been classified as having a Left/Right political stance if more than 50% of its articles have been classified as such. These cases are boldfaced in Table 2.
This is the behaviour we obtain for all the test newspapers but for the German Right-oriented newspaper: die Preußische Allgemeine Zeitung (PAZ). The German model is trained only on 12 newspapers to be compared to the 47 in English and 38 in Spanish. The incorrect classification might be an indication that diversity is a key aspect for the final model performance. Multilinguality does not help and 65% of the PAZ articles are still classified as Left oriented. We also assess the effectiveness of the English model on the German data, two close languages. We acknowledge that the topics of the USA and German newspapers might differ a lot, but the high diversity of the English training data could potentially compensate for this. The English model is able to correctly classify the German My Heimat as a Left-oriented newspaper (L: 67±3%) and PAZ as a Right-oriented one (R: 58±5%). We again attribute the difference to the German model being trained on a corpus lacking diversity. When we use the multilingual system, the dominant factor distinguishing the outputs is the language itself rather than the stance. The addition of English data is insufficient to alter the classification significantly. When we use the English system, the language does not play a role any more and only the stance features are considered. When we apply the English model to the Catalan newspapers we do not obtain satisfactory results though (95±1% for the Left but 16±3% for the Right newspaper) showing that the relatedness across languages is important. The multilingual model however properly detects the stance of the Catalan newspapers probably because it has been trained with an heterogeneous corpus that includes a related language (Spanish). We are able to perform zero-shot language transfer classification when we deal with close related languages.
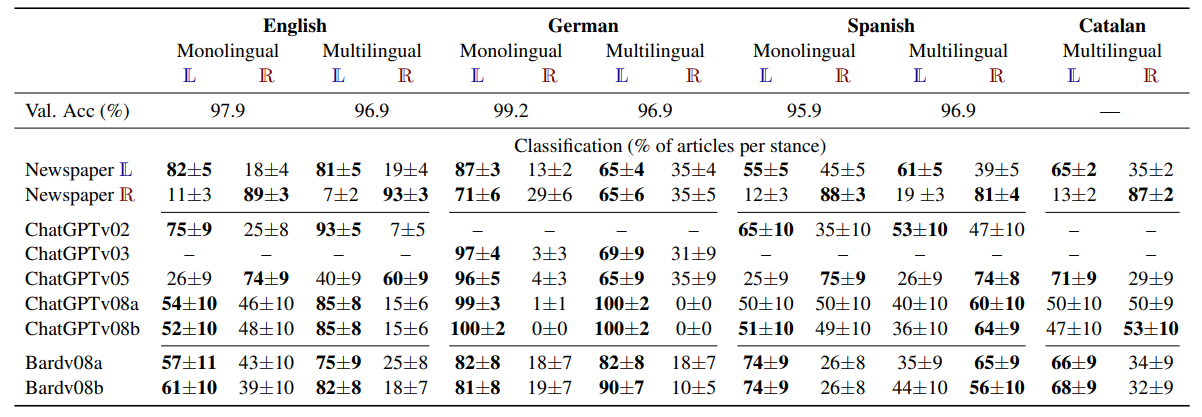
Coarse Classification with ILM-generated Articles. The bottom part of Table 2 details the results. We first focus on the English and Spanish models as the German one did not properly classify our test newspapers. The most relevant aspect to notice in ChatGPT is the strong change in political stance between February (v02) and May (v05) followed by a movement towards neutrality in August (v08). We checked that this polarity change is not an effect of the length of the outputs —the major shallow change in the generated articles. The training data in English has 5,730L–6,988 R articles with 584<length (words)<624 (similar to ChatPGTv05 length) and 4,563 L-7,127 R articles with 331< length<371 (similar to ChatGPtv02). In both cases the number of articles is larger for the Right stances, but the prediction for ChatGPTv02 clearly points towards the Left, rejecting the hypothesis that length plays a role in the classification. A similar things happens for Spanish. According to our models, the May 24th version of editorial line close to the right ideology, which differs from the ideology of the previous versions. Notably, this period corresponds drop in several task according to Chen et al. (2003). The German and Catalan outputs would still show an imprint from the Left ideology also in v05 but more diverse training data would be needed to confirm this with our monolingual models. It is interesting to notice that if we use the english monolingual model for German and Catalan, we still het the Left imprint (60±10% for German and 87±7% for Catalan). So we have indications that the political stance of ChatGPT depend on the language, which is not surprising in a data-driven system. The last version, ChatGPTv08, produces the most neutral texts, with only German clearly leaning towards the Left. The two generations, v08a and v08b, show that results are robust and are not tied to a particular generation.
There is only a version available for multilingual Bard that covers our time frame.[7] The variation between generations is larger for Bard than for ChatGPT but, comparing v08 versions, Bard points towards the Left in a more consistent way across languages. Bard’s political orientation can also be determined by its answers to political test or quiz questions. The Political Compass (PC) site[8] defines 62 propositions to identify the political ideology —with an European/Western view— in two axes: economic policy (Left–Right) and social policy (Authoritarian–Libertarian), both in the range [-10,10]. Each proposition is followed by 4 alternatives: strongly agree, agree, disagree and strongly disagree. When prompted with the questionnaire,[9] Bard’s scores are (-6.50, -4.77) for English, (-8.00, -7.13) for German, (-5.75, -4.15) for Spanish and (-6.75, -4.56) for Catalan, where the first number corresponds to the economic policy and the second to the social policy. The results are in concordance with Table 2 and give an indirect validation of our method which does not rely on direct questions.[10]
This kind of analysis is not possible with ChatGPT any more as it refrains from expressing opinions and preferences, demonstrating the relevance of an approach that detects the leaning in a more indirect way. Also notice that these questionnaires are well-known and public, so it would be easy to instruct a LM to avoid the questions or react to its propositions in a neutral manner. Previous work used only political tests and questionnaires to estimate ChatGPT’s orientation. Hartmann et al. (2023) used PC, 38 political statements from the voting advice application Wahl-O-Mat (Germany) and 30 from StemWijzer (the Netherlands) to conclude that ChatGPT’s ideology in its version of Dec 15 2022 was pro-environmental and left-libertarian.
A study conducted by the Manhattan Institute for Policy Research[11] reported that ChatGPT tended to give responses typical of Left-of-center political viewpoints for English (Rozado, 2023). The authors administered 15 political orientation tests to the ChatGPT version of Jan 9. Their results are consistent with our evaluation of the Feb 13 model. Finally, Motoki et al. (2023) performed a battery of tests based on PC to show that ChatGPT is strongly biased towards the Left. The authors do not state the version they use, but the work was submitted on March 2023. All these results are therefore before the move to the Right we detected in May.
[7] Notice that the version we use does not officially support Catalan, but native speakers confirmed that generations are mostly correct and fluent with few grammatical mistakes.
[8] https://www.politicalcompass.org/test (accessed between 13th and 20th August 2023)
[9] The Spanish questionnaire was translated into Catalan, as the questionnaire was not available.
[10] Even though, similarly to people, it is possible for an ILM to say one thing (chose an option for a proposition) and act (write a text) in an inconsistent way.
[11] A conservative think tank according to Wikipedia.