
Authors:
(1) Arindam Mitra;
(2) Luciano Del Corro, work done while at Microsoft;
(3) Shweti Mahajan, work done while at Microsoft;
(4) Andres Codas, denote equal contributions;
(5) Clarisse Simoes, denote equal contributions;
(6) Sahaj Agarwal;
(7) Xuxi Chen, work done while at Microsoft;;
(8) Anastasia Razdaibiedina, work done while at Microsoft;
(9) Erik Jones, work done while at Microsoft;
(10) Kriti Aggarwal, work done while at Microsoft;
(11) Hamid Palangi;
(12) Guoqing Zheng
(13) Corby Rosset;
(14) Hamed Khanpour;
(15) Ahmed Awadall.
Table of Links
Teaching Orca 2 to be a Cautious Reasoner
B. BigBench-Hard Subtask Metrics
C. Evaluation of Grounding in Abstractive Summarization
F. Illustrative Example from Evaluation Benchmarks and Corresponding Model Output
Abstract
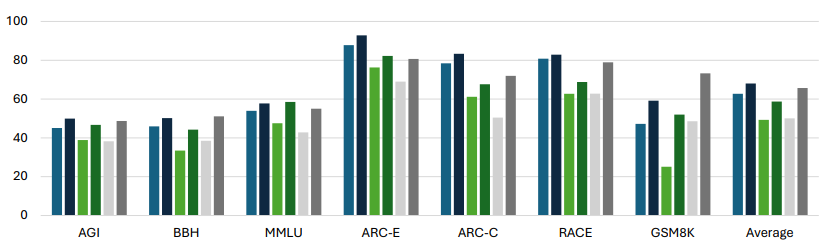
Orca 1 learns from rich signals, such as explanation traces, allowing it to outperform conventional instruction-tuned models on benchmarks like BigBench Hard and AGIEval. In Orca 2, we continue exploring how improved training signals can enhance smaller LMs’ reasoning abilities. Research on training small LMs has often relied on imitation learning to replicate the output of more capable models. We contend that excessive emphasis on imitation may restrict the potential of smaller models. We seek to teach small LMs to employ different solution strategies for different tasks, potentially different from the one used by the larger model. For example, while larger models might provide a direct answer to a complex task, smaller models may not have the same capacity. In Orca 2, we teach the model various reasoning techniques (step-by-step, recall then generate, recall-reason-generate, direct answer, etc.). Moreover, we aim to help the model learn to determine the most effective solution strategy for each task. We evaluate Orca 2 using a comprehensive set of 15 diverse benchmarks (corresponding to approximately 100 tasks and over 36K unique prompts). Orca 2 significantly surpasses models of similar size and attains performance levels similar or better to those of models 5-10x larger, as assessed on complex tasks that test advanced reasoning abilities in zero-shot settings. We make Orca 2 weights publicly available at aka.ms/orca-lm to support research on the development, evaluation, and alignment of smaller LMs.

1 Introduction
Large Language Models (LLMs) are enabling more natural and sophisticated interactions between humans and machines, enhancing user experience in existing applications like coding [3], web search [36], chatbots [45, 56], customer service and content creation. This transformation brought by LLMs is also paving the way for new innovative AI applications.
Scaling LLMs like GPT-4 [44] and PaLM-2 [1] to ever more parameters led to emergent abilities [63] unseen in smaller models (less than ∼ 10B parameters), most notably the remarkable ability to reason zero-shot [23]. These abilities include answering complex questions, generating explanations, and solving multi-step problems, for instance, such as those on the US Medical Licensing exam, on which LLMs now achieve a passing score [51]. Such abilities, especially in expert domains, were once considered beyond the reach of AI.
Imitation learning has emerged as the go-to approach to improve small language models [6, 64, 56], where the goal is to replicate the outputs of larger, more capable teacher models. While these models can produce content that matches the style of their teachers, they often fall short of their reasoning and comprehension skills [13]. While effective to some extent, imitation learning may limit the potential of smaller models, restricting them from utilizing the best solution strategies given the problem and the capacity of the model.
In this work, we continue to pursue the question of how we can teach smaller LMs to reason. The objectives of Orca 2 are two-fold. Firstly, we aim to teach smaller models how to use a suite of reasoning techniques, such as step-by-step processing, recall-then-generate, recall-reason-generate, extract-generate, and direct-answer methods. Secondly, we aspire to help these models decide when to use the most effective reasoning strategy for the task at hand, allowing them to perform at their best, irrespective of their size.
Like Orca 1, we utilize more capable LLMs to demonstrate various reasoning strategies across various tasks. However, in Orca 2, the reasoning strategies are carefully tailored to the task at hand, bearing in mind whether a student model is capable of the same behavior. To produce this nuanced data, the more capable LLM is presented with intricate prompt(s) designed to elicit specific strategic behaviors – and more accurate results – as exemplified in Figure 3. Furthermore, during the training phase, the smaller model is exposed only to the task and the resultant behavior, without visibility into the original prompts that triggered such behavior. This Prompt Erasure technique makes Orca 2 a Cautious Reasoner because it learns not only how to execute specific reasoning steps, but to strategize at a higher level how to approach a particular task. Rather than naively imitating powerful LLMs, we treat them as a reservoir of behaviors from which we carefully select those best suited for the task at hand.
Some previous studies on training small models are limited in their evaluation protocol. They often rely on small number of tasks or on using other models for auto-evaluation by asking them to compare the outputs of two systems with a prompt like “given responses from system 1 (reference) and system 2 (target), which one is better?”. However, previous work [13, 42, 60, 67] has demonstrated that this approach has several drawbacks. In this work, we provide a comprehensive evaluation comparing Orca 2 to several other models. We use a total of 15 benchmarks (covering ∼100 tasks and over 36,000 unique prompts). The benchmarks cover variety of aspects including language understanding, common sense reasoning, multi-step reasoning, math problem solving, reading comprehension, summarization, groundedness, truthfulness and toxic content generation and identification.
Our preliminary results indicate that Orca 2 significantly surpasses models of a similar size, even matching or exceeding those 5 to 10 times larger, especially on tasks that require reasoning. This highlights the potential of endowing smaller models with better reasoning capabilities. However Orca 2 is no exception to the phenomenon that all models are to some extent constrained by their underlying pre-trained model (while Orca 2 training could be applied any base LLM, we report results on LLaMA-2 7B and 13B in this report). Orca 2 models have not undergone RLHF training for safety. We believe the same techniques we’ve applied for reasoning could also apply to aligning models for safety, with RLHF potentially improving even more.
This paper is available on arxiv under CC 4.0 license.