
Authors:
(1) Maria Rigaki, Faculty of Electrical Engineering, Czech Technical University in Prague, Czech Republic and [email protected];
(2) Sebastian Garcia, Faculty of Electrical Engineering, Czech Technical University in Prague, Czech Republic and [email protected].
Table of Links
Conclusion, Acknowledgments, and References
3 Background and Related Work
This section provides background information and summarizes the related work in machine learning malware evasion and model extraction. It also presents some relevant background information on reinforcement learning and the environments used for training agents for malware evasion.
3.1 Reinforcement Learning
Reinforcement Learning (RL) is a sub-field of machine learning where the optimization of a reward function is done by agents that interact with an environment. The agent performs actions in the environment and receives back observations (view of the new state) and a reward. The goal of RL is to train a policy, which instructs the agent to take certain actions to maximize the rewards received over time [40].
More formally, the agent and the environment interact over a sequence of time steps t. At each step, the agent receives a state from the environment st and performs an action at from a predefined set of actions A. The environment produces the new state st+1 and the reward that the agent receives due to its action. Through this interaction with the environment, the agent tries to learn a policy π(a|s) that maps the probability of selecting an action a given a state s, so that the expected reward is maximized. One of the essential aspects of RL is the Markov property, which assumes that future states of the process only depend on the current state.
Some of the most successful RL algorithms are model-free approaches, i.e., they do not try to build a model of the environment. A downside of model-free algorithms is that they tend to require a lot of data and work under the assumption that the interactions with the environment are not costly. In contrast, model-based reinforcement learning algorithms learn a model of the environment and use it to improve the policy learning. A fairly standard approach for modelbased RL is to alternate between policy optimization and model learning. During the model learning phase, data is gathered from interacting with the environment, and a supervised learning technique is employed to learn the model of the environment. Subsequently, in the policy optimization phase, the trained model explores methods for enhancing the policy [21]..
In terms of security applications, reinforcement learning has been proposed for use in several applications such as honeypots [11,17], IoT and cyber-physical systems [26,42], network security [44], malware detection [13,43], and malware evasion [2,14,22,23,29,30,38]. Most malware evasion papers use Malware-gym or extensions of it to test their proposed algorithms, therefore we present the basic concepts of the environment in more detail below.
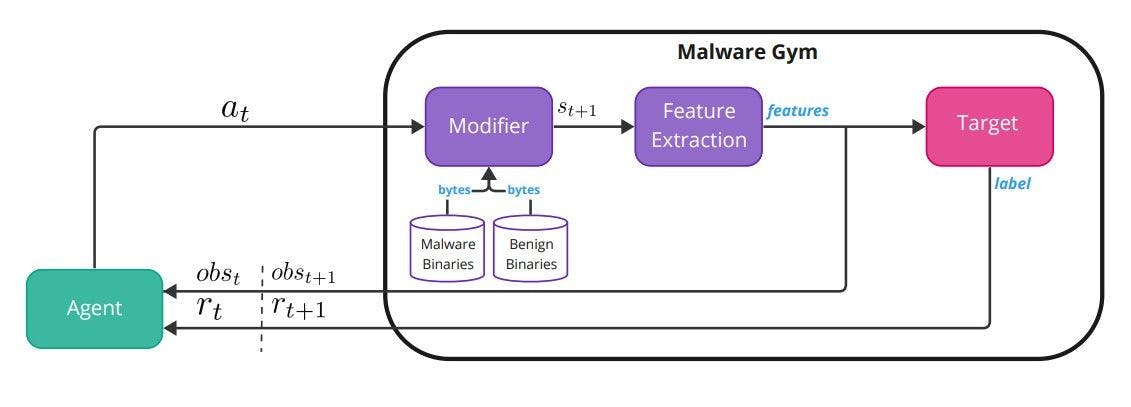
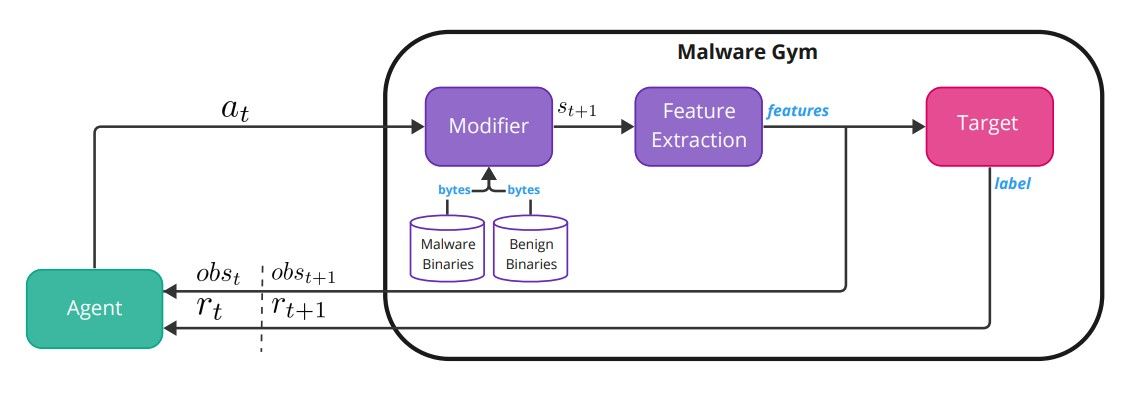
Malware-Gym The Malware-Gym environment is a reinforcement learning environment based on OpenAI Gym [5], and it was first introduced in [2]. Figure 1 shows the internal architecture of the environment.
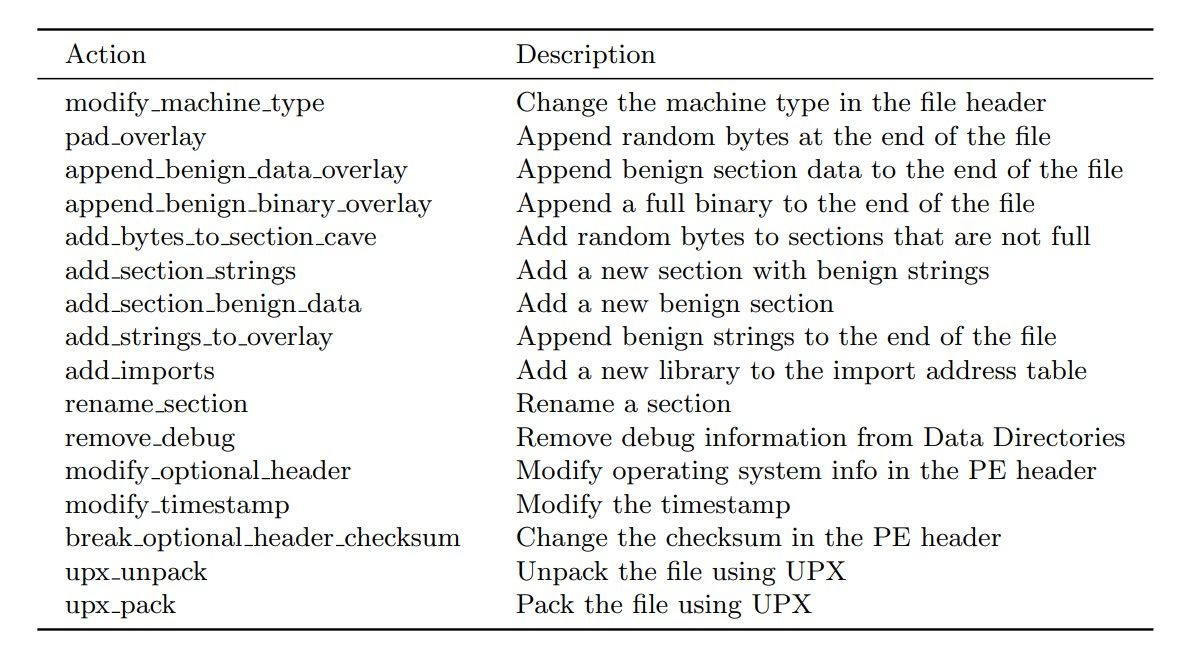
The environment encapsulates a target model, which is considered a black box. The target takes as input extracted features from a binary file and outputs a label or a prediction score. The binary file bytes are the state st and the extracted features is the observation ot, which the agent receives from the environment at time t. The observation is also fed into the target model that outputs a score or a label. The score is transformed into a reward rt that is returned to the agent that has to decide which action to take, at. The action is fed back into the environment, which modifies the binary through the transition function (modifier) to produce the next binary state st+1, observation ot+1, and reward rt+1. The list of available actions in the latest version of the Malware-Gym can be found in Table 1. The actions listed aim to preserve functionality, and ideally, the modified binary should still be valid. Some of the actions require a benign dataset in order to use strings and sections from benign files.
The reward is calculated based on the output of the classifier/target. If the score is below a predetermined decision threshold, the binary is considered benign, i.e., it evaded the target, and the returned reward equals 10. If the score is higher than the threshold, the binary is considered malicious, and the reward is calculated as the difference between the previous and current scores. The process continues until the binary is evasive or a predetermined number of maximum iterations is reached. The agent receives the current observation (features) and the reward and decides on the next action unless the malware is evasive, where it moves to the next binary. The agent’s goal is to learn a policy π that generalizes well and can be applied to future malicious binaries.
Table 1. Action space in latest Malware-Gym
3.2 Malware Evasion
The main goal of malware evasion is to make the malware undetectable by security systems so that it can perform its malicious activities unnoticed. Malware creators continuously develop new techniques to evade detection, which makes it difficult for security experts to keep up with the evolving threat landscape. The concept has evolved to include the evasion of machine learning classifiers and also to use machine learning techniques to evade antivirus (AV) systems. For the purpose of this work, we are mainly interested in machine learning approaches that attackers may use to generate evasive fully functional Windows PE malware so that they can not be detected by malware classifiers and AVs.
There have been several works on this topic, and detailed taxonomies and definitions can be found in the following surveys [10,24]. Anderson et al. [2] created the Malware-Gym and were the first work that generated adversarial malware that aimed to be functionality preserving. They used the Actor-Critic model with Experience Replay (ACER) algorithm and tested against the original Ember model. Other works extended the Malware-Gym and tested different algorithms such as Double Deep Q-Network(DQN) [14], Distributional Double DQN [22], and REINFORCE [30].
Apart from testing different algorithms, several authors proposed changes to the reward function [12,22]. MAB-malware [38] is another RL framework that is based on multi-armed bandits (MAB). MAB and AIMED [22] are the only works that assume that the target model provides only a hard label instead of a prediction score. The different works propose different numbers of permitted modifications, varying from as low as 5 to as high as 80. However, none of the prior work puts a constraint on the number of queries to the target or discusses whether unlimited query access is a realistic scenario.
Other black-box attacks for the evasion of malware classifiers proposed different approaches such as genetic algorithms [9], explainability [33], or using simpler but effective techniques such as packing [6].
3.3 Model Extraction
Model extraction or model stealing is a family of attacks that aim to retrieve a model’s parameters, such as neural network weights or a functional approximation, using a limited query budget. These types of attacks are usually tested against Machine Learning as a Service (MLaaS) applications. The majority of the model extraction attacks use learning-based approaches, where they query the target model with multiple data samples X and retrieve labels or prediction scores y to create a thief dataset. Using the thief dataset, they train a surrogate model that behaves similarly to the target model in the given task. Model extraction attacks may have different goals [19]. In a fidelity attack, the adversary aims to create a surrogate model that learns the decision boundary of the target as faithfully as possible, including the errors that the target makes. These surrogate models can be used later in other tasks, such as generating adversarial samples. In a task accuracy attack, the adversary aims to construct a surrogate model that performs equally well or better than the target model in a specific task such as image or malware classification. The attacker’s ultimate goal affects the selection of the thief dataset, the metrics for a successful attack, and the attack strategy itself.
Learning-based model extraction attacks use different strategies to select the samples they use for querying the target, such as active learning [7,28], reinforcement learning [27], generative models [34], or just selecting random data [8]. In the security domain, model extraction has been proposed as the first step of an attack that aims to generate evasive malware [33,16,32]. Both [33] and [32] generate evasive malware in a two-step approach: first creating a surrogate and then using it to evade the target. Hu et al. [16] use a Generative Adversarial Network (GAN) and a surrogate detector to bypass a malware detector that works with API calls. Neither [16] and [33] are concerned with the number of queries they are making to the target, while in [32] the authors measured only the query efficiency of the model extraction and not that of the subsequent task of the malware evasion.
This paper is available on arxiv under CC BY-NC-SA 4.0 DEED license.