
In the summer of 2023, a cheeky blog post titled "
Kafka was originally developed at LinkedIn and open-sourced in 2011. It is written in Java and Scala and is in wide deployment, but it is a large, complex, and difficult project to launch and manage. The Kafka API has been established and is supported by other players in this space, which makes for a robust community and exciting developments.
Let’s Dive In
Originally designed for LinkedIn’s data centers, Kafka's migration to the cloud has presented significant hurdles. The replication strategy often results in higher inter-availability zone bandwidth costs, and its management typically necessitates a dedicated team. This is the precise problem that WarpStream aims to address with its innovative solution.
As previously mentioned, it is a Kafka protocol-compatible data streaming platform that runs directly on top of any commodity object store. Name the cloud, and it appears they run on it. I’m personally a big fan of the Go language, so I liked that it was developed in Go. What’s next?
Using WarpStream
I’m doing this in Ubuntu running in WSL on Windows 11. The
|
curl https://console.warpstream.com/install.sh | bash |
|---|
With that installed, then I issued the warpstream demo command. This will do the following:
- Automatically sign you up for a temporary account that is valid for 12 hours.
- Run an in-memory producer that will produce small JSON documents to a stream periodically.
- Run an in-memory WebAssembly consumer that consumes the JSON documents and prints them to the standard console.
This is what it looked like. The bottom line in green is the URL that I pasted into my web browser, which I’ll get to in a moment.
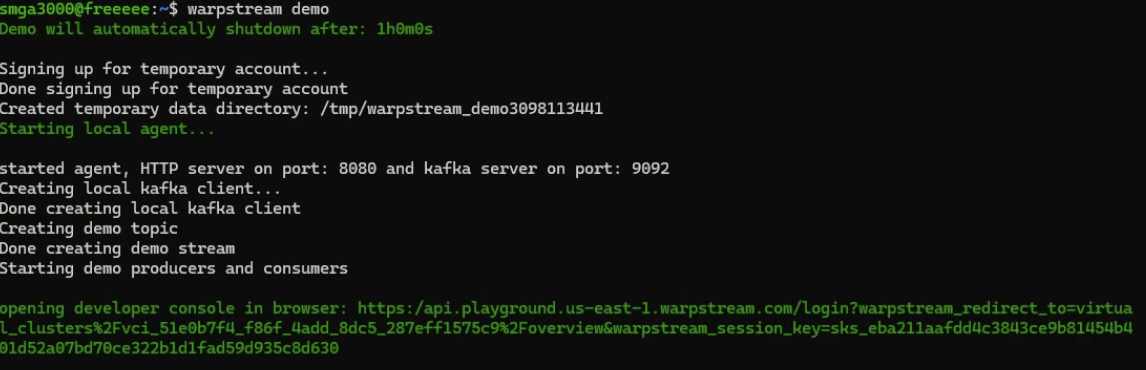
After more than a screenful of feedback, I get the suggestion in blue to execute that comment in another terminal, and then we see the data getting produced to a topic and 4 different partitions.
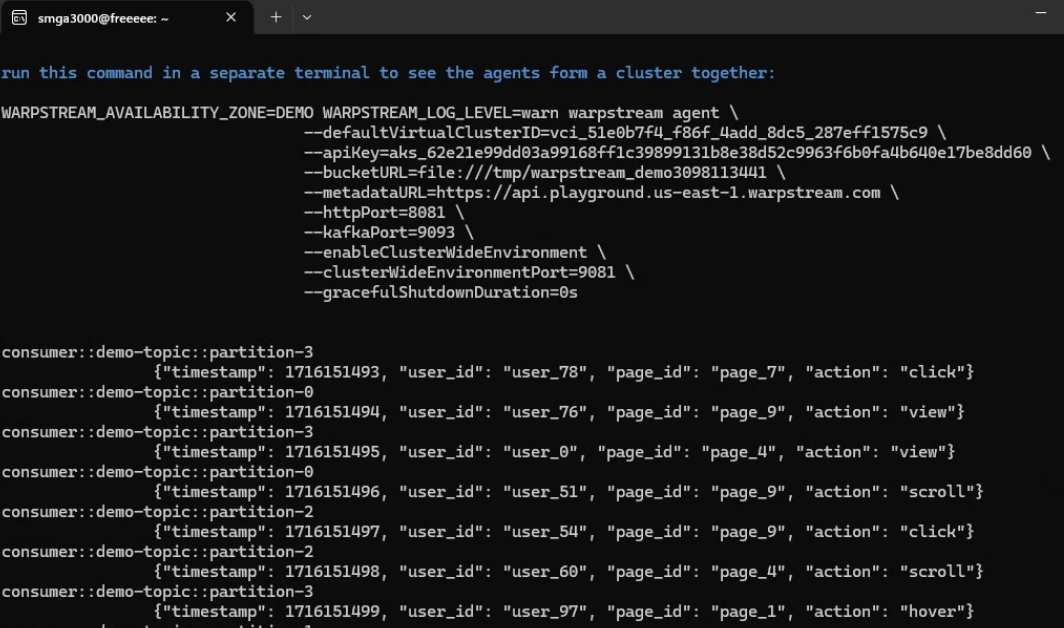
\With that all running, I pasted the URL into my browser and I saw this immediately. We see two agents running in the cluster overview
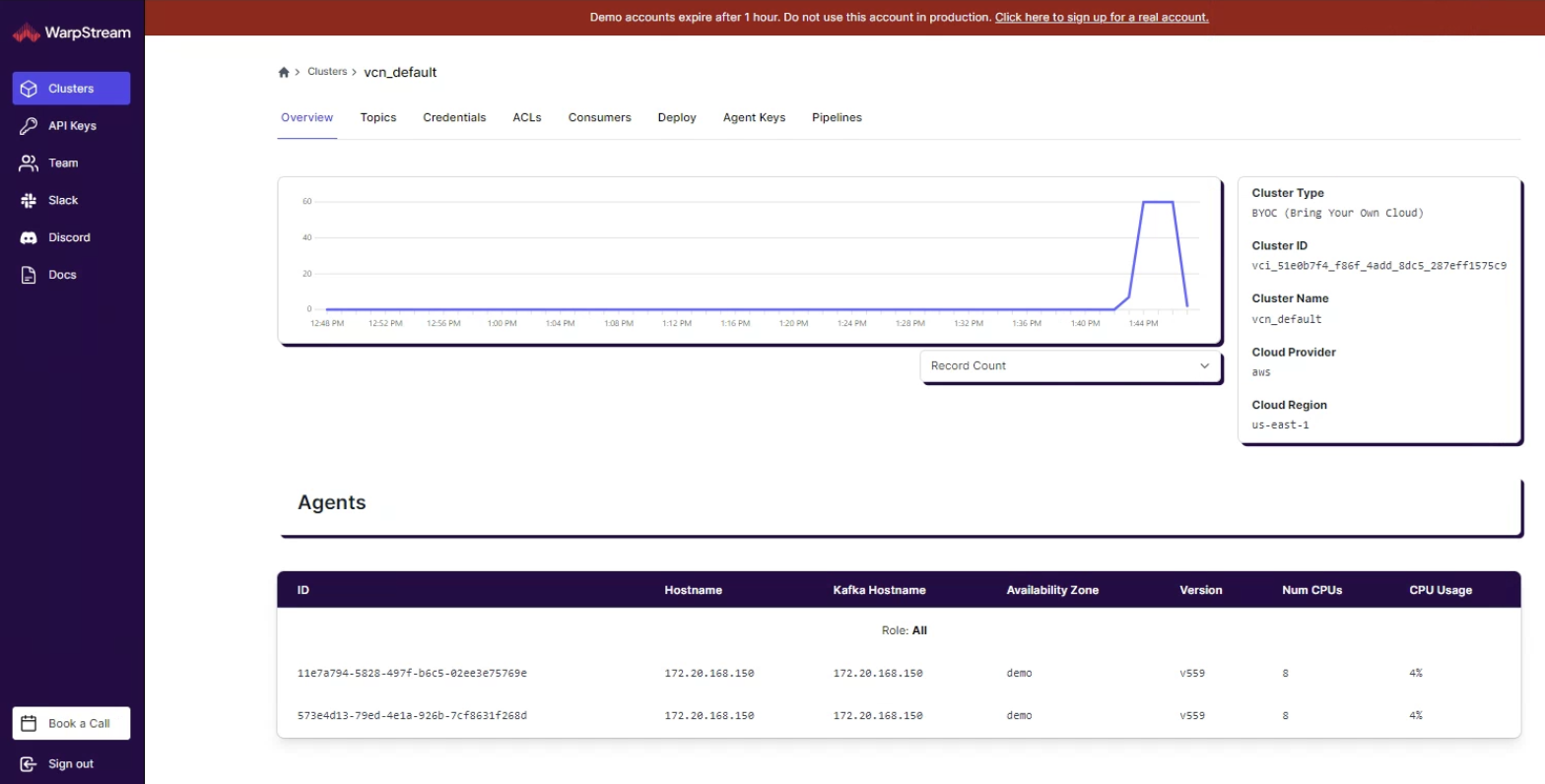
Curious about the activity, I decided to delve into the topics. There, I found our topic with its four partitions, all showing write activity from the demo command. This whole demo is ephemeral, so you can try it out; it shuts itself down after an hour, so don’t try doing anything serious.
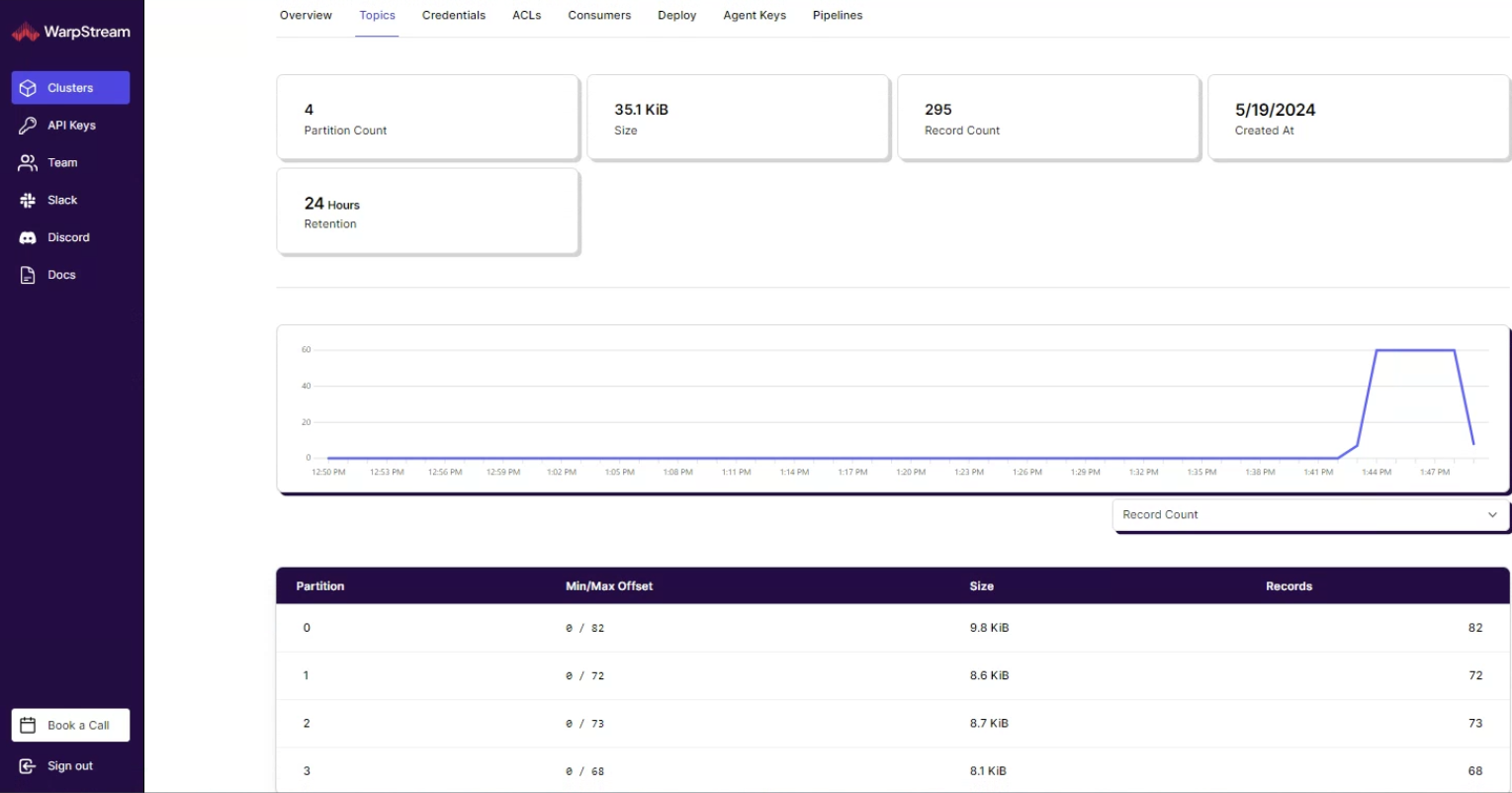
There are a number of other features in there that I tried out; they’ve definitely bundled a lot of ease of use into the interface. If I had a nit to pick, it’s the UI for pop-up dialogs for creating and deleting objects; they have no ‘cancel’ option, and you have to hit the left navigation to bail out. There is a very cool startup wizard when you start building either a Serverless or BYOC cluster. It creates a temporary virtual cluster for a tutorial that then walks you through each step of getting started. The function seems to trigger if it is your first time creating a server in your account.
Summary
There are a lot of cool features in the WarpStream product that make it easy to set up and use, crazy easy. If you want a deep dive, I suggest their blog post that I linked in the intro, and for you to try it yourself. The fact that you can drop it into an existing Kafka setup and have it basically “just work”, is very compelling. If I had a nit to pick, it’s that there isn’t an open-source component, but on the other hand, it’s a product on top of an open protocol, which is basically how a lot of open-source companies monetize. They are currently sponsoring
So, what the heck is WarpStream? It’s a really powerful, easy-to-use, Kafka API-compatible replacement for Apache Kafka. It should lower your operational overhead for running Kafka and make it cheaper to run your streaming workloads. If you’re streaming with Kafka or one of the other protocols, it’s worth checking out.
**Check out my other What the Heck is… articles at the links below:
What The Heck Is DuckDB? What the Heck Is Malloy? What the Heck is PRQL? What the Heck is GlareDB? What the Heck is SeaTunnel? What the Heck is LanceDB? What the heck is SDF? What the Heck is Paimon? What the Heck is Proton? What the Heck is PuppyGraph? What the Heck is GPTScript?
**