
Authors:
(1) Muzhaffar Hazman, University of Galway, Ireland;
(2) Susan McKeever, Technological University Dublin, Ireland;
(3) Josephine Griffith, University of Galway, Ireland.
Table of Links
Conclusion, Acknowledgments, and References
A Hyperparameters and Settings
E Contingency Table: Baseline vs. Text-STILT
4 Results
4.1 RQ1: Performance Improvement
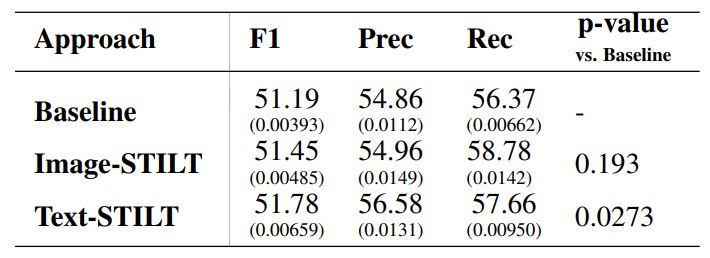
Text-STILT was found to outperform Baseline, at a level of statistical significance. Figure 3 and Table 4 show the performance distribution of each approach, with 10 random restarts each. The Wilcoxon Signed-Rank test resulted in p-values of 0.193 and 0.0273 for Baseline vs. Image-STILT and Baseline vs. Text-STILT, respectively.
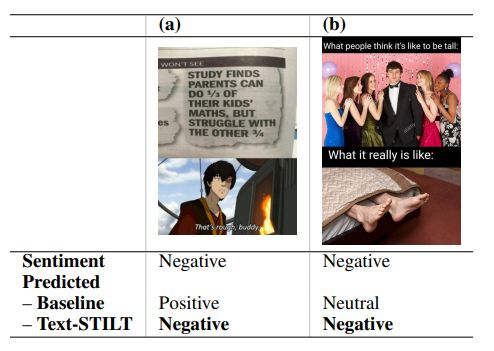
To our knowledge, Text-STILT is the first approach to successfully incorporate supplementary unimodal data into the training of multimodal meme classifiers showing a statistically significant performance improvement. However, our results do not indicate why Text-STILT was effective. We posit that while each meme’s semantics rely on both the image and text modalities, memes that contain longer texts and/or a textual structure that hints at the meme’s overall sentiment are more accurately classified by Text-STILT (see examples in Table 5). Consider the meme in Table 5(b): While the negative component is represented visually, that is, the bottom image segment, the structure of the text “what people think... what it really is like...” strongly suggests a negative inversion of something normally considered to be positive. Thus, its negative sentiment could be inferred largely from text alone. More rigorous investigation of the relationship between text and meme sentiment analysis is warranted.
Although Text-STILT significantly outperformed Baseline, Image-STILT did not. Although Image-STILT shows higher mean, maximum, and minimum performance than Baseline, the distribution (see the violin plot in Figure 3) indicates that the two performed similarly. This could be attributed to the distinct role of visual symbols in memes, which derive their meaning from popular usage rather than literal connotations. Consider the memes in Table 3, each made using highly popular meme templates: Success Kid [2] and Bad Luck Brian [3], respectively. These have come to symbolise specific meanings through online usage, which is distinct from what is literally shown. In the case of Bad Luck Brian, see Table 3(d), a teenage boy smiling in a portrait does not inherently convey tragedy, or misfortune, but this connotation stemmed from the template’s usage in online discourse.
In contrast, the unimodal images in Table 3 show a visual language that is less culturally specific, i.e. a serene beach has positive connotations and a disfigured zombie-esque head conveys negative ones. The cultural specificity of visual symbols in memes likely contributed to Image-STILT’s lack of significant performance improvement. These may explain similar observations by Suryawanshi et al. (2020), as discussed in Section 2.2, and would suggest that the transfer of visual sentiment skills from unimodal images to multimodal meme classifiers may be inherently limited.
4.2 RQ2: Limited Labelled Memes
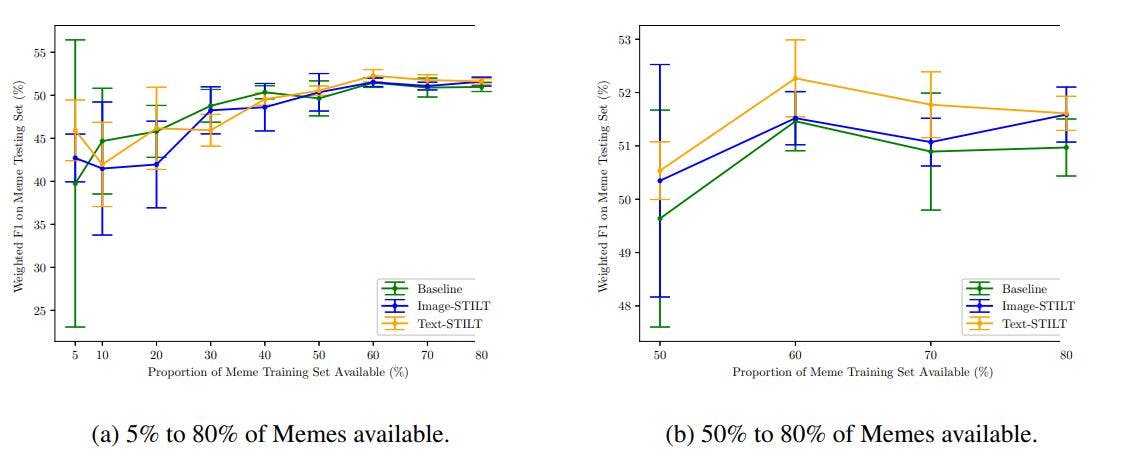
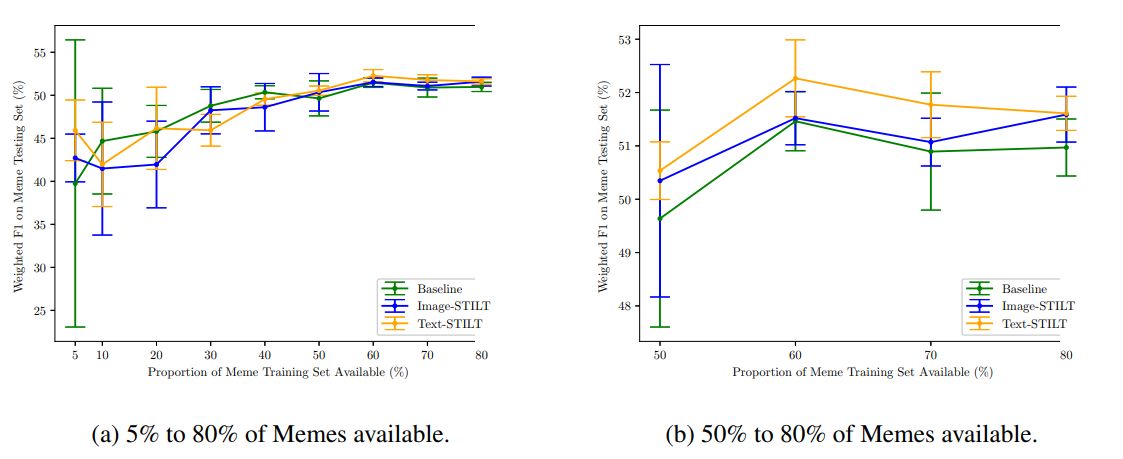
We found that Text-STILT significantly improves performance over Baseline across varying amounts of labelled meme availability between 50% and 80% (shown in Figure 4b). Within this range, while both intermediate training approaches consistently showed higher mean performance than Baseline, only Text-STILT showed a significant performance improvement and Image-STILT did not; p-values were 0.000109 for Baseline vs. Text-STILT and 0.0723 for Baseline vs. Image-STILT, respectively.
Based on these measurements, we found that Text-STILT was still able to outperform Baseline while using only 60% of the available labelled memes. Figure 5 shows the performance distribution of Baseline with 100% memes available and Text-STILT with 50% and 60% memes available.
We also noted that neither Image-STILT nor Text-STILT was found to significantly improve performance over Baseline across the entire range of availability of labelled memes from 5% to 80%. Figure 4 shows the mean performance and standard deviation of Baseline, Image-STILT, and TextSTILT across this range. When hypothesis testing is applied across the entire range, neither ImageSTILT nor Text-STILT showed statistically significant improvements over Baseline, with p values of 0.667 and 0.985, respectively.
![Figure 5: Performance of Baseline trained on 100% of memes available and Text-STILT trained on [50%, 60%] of memes available.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-vgb3vvo.jpeg)
Although Text-STILT performed better than Baseline, the difference is small. Contemporary approaches show similar small differences in performance (see Appendix D). Furthermore, 41% of memes in the testing set were not correctly classified by either Text-STILT and Baseline (see Appendix E). This suggests that a significant portion of memes remain a challenge to classify. This challenge might be addressed by combining TextSTILT with other supplementary training steps.
[2] https://knowyourmeme.com/memes/success-kid-i-hatesandcastles
[3] https://knowyourmeme.com/memes/bad-luck-brian
This paper is available on arxiv under CC 4.0 license.