
Authors:
(1) Muzhaffar Hazman, University of Galway, Ireland;
(2) Susan McKeever, Technological University Dublin, Ireland;
(3) Josephine Griffith, University of Galway, Ireland.
Table of Links
Conclusion, Acknowledgments, and References
A Hyperparameters and Settings
E Contingency Table: Baseline vs. Text-STILT
3 Methodology
To address our research questions, we chose the 3-class sentiment polarity of multimodal memes as our target task as defined by Ramamoorthy et al. (2022) for our chosen dataset. Our experimental approach revolves around comparing the performance of a multimodal classifier trained only on memes (our Baseline) and those trained first on unimodal image or text data (our Image-STILT and TextSTILT models, respectively) before being trained on memes. These models are architecturally identical to each other, all trained in the Memotion 2.0 training set and tested against the Memotion 2.0 testing set to isolate the effect of unimodal intermediate training on meme sentiment classification performance. The results of the performance of the model are measured using the weighted F1-score, as defined by the authors of the selected meme dataset (Sharma et al., 2022). A detailed description of this metric is available in Appendix B.
3.1 Model Architecture
As this work does not seek to propose a new meme classifier architecture, we heavily base our model on one found in literature: the Baseline model proposed by Hazman et al. (2023). Per this previous work, we also use the image and text encoders from OpenAI CLIP (Radford et al., 2021) to represent each modality, respectively, and the same modality fusion weighting mechanism they had used. However, we added dropout and batch normalisation after encoding each modality and the fusion of these encodings, which were helpful in preventing overfitting. Figure 2 illustrates our architecture and a detailed description is presented in Appendix C.
3.2 Datasets
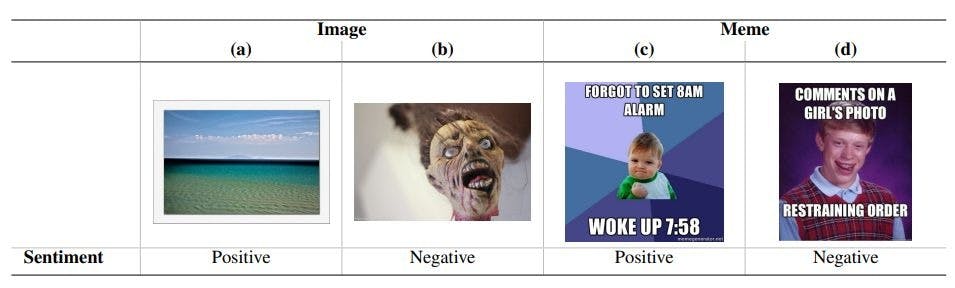
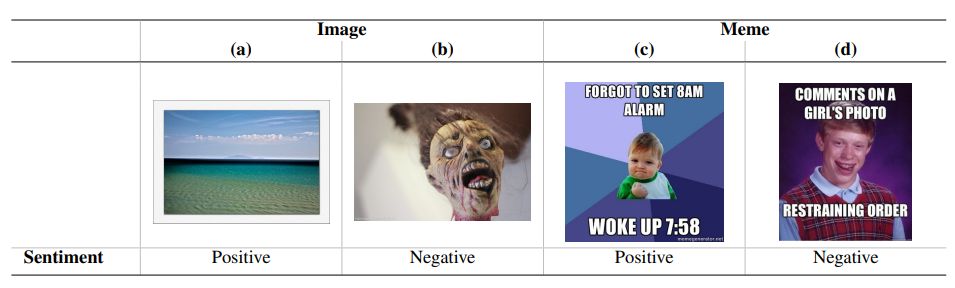
Multimodal Memes: This work uses sentimentlabelled multimodal memes from the Memotion 2.0 (Ramamoorthy et al., 2022) benchmark dataset as our target task. We did not use the earlier (Sharma et al., 2020) and later (Mishra et al., 2023) iterations of this dataset as the former did not provide a validation set and the latter focused on code-mixed languages. Each sample in this meme dataset comprises a meme collected from the web that was then labelled by multiple annotators as conveying either a Positive, Negative or Neutral sentiment. For each meme sample, the dataset presents an image file and a string of the text that was extracted using OCR with manual validation.
To assess the effectiveness of our approach on various amounts of labelled memes available for training, that is, to answer RQ2, we defined fractional training datasets by randomly sampling the memes training set at the following fractions: 5, 10, 20, 30, 40, 50, 60, 70, and 80%. For each random restart, we repeat this sampling to account for variance in model performance attributable to training data selection. Where matched pairs are needed for hypothesis testing (see Section 3.4.RQ2 below), we do not resample between training Baseline, ImageSTILT and Text-STILT models. To prevent the models from converging into a model that predicts only the most prevalent class in the training set, we balance the classes in these fractional datasets by applying weights inverse of the class distribution during sampling without replacement.
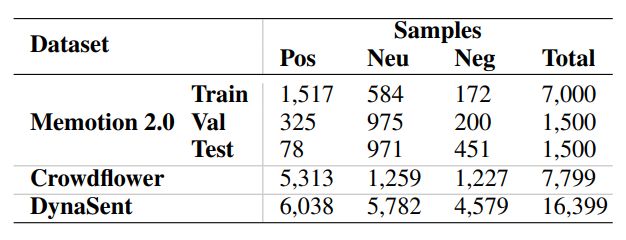
Unimodal Images and Texts: For unimodal intermediate training, we used two unimodal datasets: Crowdflower (CrowdFlower, 2016) for unimodal images, and DynaSent (Potts et al., 2021) for unimodal text. Both datasets comprise crowdsourced samples collected from social networking sites, and both contain crowd-annotated 3-class sentiment labels[1]. We included all images from the CrowdFlower dataset that we were able to fetch via the provided URLs; not all samples were retrievable. The summaries of, and examples from, these datasets are presented in Tables 2 and 1, respectively.
3.3 Training
Baseline: For each run, the model is initialised by loading pretrained weights for the encoders and randomly initialising the weights in the fusion mechanism. For our Baseline approach, the model is trained on the Memotion 2.0 training set, with early stopping at the point of minimum loss on the validation set, and evaluated against the testing set. We maintain the dataset splits defined by Ramamoorthy et al. (2022).
Unimodal STILTs – Image-STILT and TextSTILT: In our proposed approaches, the initialisation of the model is the same as for Baseline and is followed by training the model on a selected unimodal dataset while freezing the encoder of the other modality, that is, the text encoder is frozen while training on unimodal images in Image-STILT and vice versa. Unimodal training ends with early stopping based on the model’s performance on the Memotion 2.0 validation set. This model is then trained and tested on the Memotion 2.0 training and testing sets, respectively, as was done in the Baseline approach. Hyperparameters used when training on the Memotion 2.0 dataset are kept constant across all models (see Appendix A).
3.4 Experimental Approach
RQ1: To establish whether Image-STILT or Text-STILT offers a statistically significant performance improvement over Baseline, we employ the Wilcoxon Signed-Rank test. The null hypothesis in each case is that there is no significant performance difference between our Baseline approach and Image-STILT or Text-STILT, respectively. We ran 10 random-restarts for each approach: Baseline, Image-STILT, and Text-STILT. All models were trained on all memes from the Memotion 2.0 (Ramamoorthy et al., 2022) training set. Separate tests were conducted for (1) Baseline vs. Image-STILT and (2) Baseline vs. Text-STILT; resulting in a total of 10 pairs each for hypothesis testing.
RQ2: To characterise the performance benefits of Image-STILT or Text-STILT with limited availability of labelled memes, we train Baseline, Image-STILT and Text-STILT on varying amounts of training memes. For each approach and at each of the training set sizes, we ran five random-restarts, resulting in 45 observations for each Baseline vs. Image-STILT and Baseline vs. Text-STILT, separately. For each random restart, we resample the training set, we define a matched pair (as required by Wilcoxon Signed-Rank test assumptions) as the performance of two models having been trained on the same set of memes. We performed a Wilcoxon Signed-Rank test across the entire range of labelled meme availability, but separately for Baseline vs. Image-STILT and Baseline vs. Text-STILT.
[1] CrowdFlower’s Highly Negative and Highly Positive are treated as Negative and Positive.
This paper is available on arxiv under CC 4.0 license.