
Authors:
(1) Rui Cao, Singapore Management University;
(2) Ming Shan Hee, Singapore University of Design and Technology;
(3) Adriel Kuek, DSO National Laboratories;
(4) Wen-Haw Chong, Singapore Management University;
(5) Roy Ka-Wei Lee, Singapore University of Design and Technology
(6) Jing Jiang, Singapore Management University.
Table of Links
4 PROPOSED METHOD
4.1 Overview
Recall that the key idea of our method is to elicit image details that are critical for hateful content detection, such as the gender and race of the people in the image. Because these details are not always included in automatically generated image captions, we propose relying on VQA to obtain such critical information, where the questions are carefully curated to elicit demographic and other relevant information. We opt to use zero-shot VQA because (1) for the intended type of questions, we do not have any VQA training data to train our own model, and (2) recent work has demonstrated promising performance of zero-shot VQA.
Specifically, we prompt the PVLM with 𝐾 probing questions and regard the set of 𝐾 answers from the PVLM as image captions, which we refer to as Pro-Cap. We then combine the original text T with Pro-Cap as input to a hateful meme detection model. We experiment with two alternative hateful meme detection models: one based on BERT encoding, and the other based on PromptHate, a recently proposed prompting-based hateful meme detection model.
In the rest of this section, we first present the details of how we design our VQA questions to elicit the most critical details of an image for hateful meme detection. We then explain how the generated Pro-Cap is used by two alternative hateful meme detection models.
4.2 Design of VQA Questions
We leverage PVLMs for zero-shot VQA to generate Pro-Cap as image captions. We want Pro-Cap to provide not only a general description of the image but also details critical for hateful meme detection. To obtain a general caption of the image, we design the first probing question to inquire about the generic content of the image, as shown in Table 2. However, such generic captions may be insufficient for hateful meme detection as hateful content usually targets persons or groups with specific characteristics, such as race, gender, or religion [5, 12]. Additionally, previous studies have shown that augmenting image representations with entities found in the image or demographic information of people in the image significantly aids hateful meme detection [14, 37]. Such details may be missing in generic image captions. Therefore, we design additional questions that aim to bring out information central to hateful content. This aligns the generated image captions more closely with the goal of hateful meme detection. Specifically, the high-level idea is to ask questions about common vulnerable targets of hateful content. Inspired by [24], which categorizes the targets of hateful memes into Religion, Race, Gender, Nationality, and Disability, we ask questions about these five types of targets. For example, to generate image captions that indicate the race of the people in an image, we can ask the following question: what is the race of persons in the image? We list the five questions designed for these five types of targets in Table 2. Additionally, we observe that some animals, such as pigs, are often depicted in hateful memes, frequently as a means to annoy Muslims. With this consideration, we also design a question asking about the presence of animals in the image.
In [3], the author claimed that PVLMs may hallucinate nonexistent objects. For example, even when there is nobody in an image, PVLMs may generate an answer about race in response to the question what is the race of the person in the image?. To prevent such misleading information, we use two validation questions. Specifically, we inquire about the existence of persons and animals. Only when the PVLM responds that a person or an animal exists will we include in the Pro-Cap the answers to those person-related or animal-related questions. For instance, if the answer to the question validating the existence of people indicates that nobody is present, we will ignore all answers from questions asking about religion, race, gender, nationality, and disability.
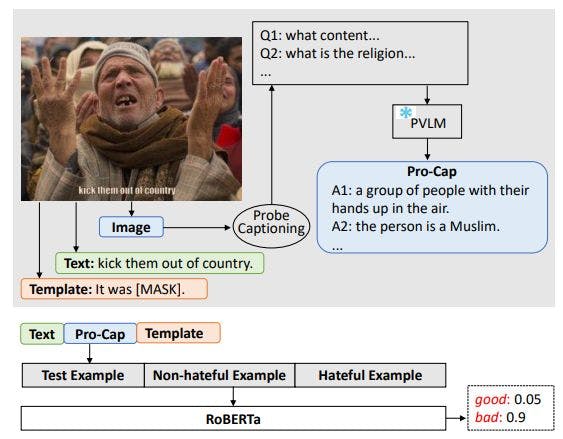
We use C to represent the concatenation of the answers to the probing questions that are finally included as part of the Pro-Cap based on the validation results. We will then concatenate T and C together as input to a purely text-based hateful meme classification model, as shown at the bottom of Figure 1.
4.3 BERT-based Detection Model


4.4 PromptHate for Hateful Meme Detection
Next, we introduce the second hateful meme classification model, PromptHate [2], which employs a prompt-based method to classify memes. PromptHate was developed to better leverage contextual background knowledge by prompting language models. Given a test meme, PromptHate first uses an image captioning model to obtain generic image captions. It then concatenates the meme text, the image captions, and a prompt template into S: It was [MASK]., to prompt a language model (LM) to predict whether the meme is hateful. Specifically, it compares the probability of the language model predicting [MASK] to be a positive word (e.g., good) given the context, versus the probability of predicting a negative word (e.g., bad). The approach also includes one positive and one negative example in the context, and [MASK] will be replaced by their respective label words. An overview of PromptHate is shown in Figure 2. For further details, please refer to [2].
In [2], PromptHate utilizes ClipCap [25] to generate image captions. In this work, we replace this with Pro-Cap C. We then represent every meme O as O = [T, C, S]. With these inputs, the language models (LMs), for instance, RoBERTa [21], generate confidence scores for the masked word over their vocabulary space, V:
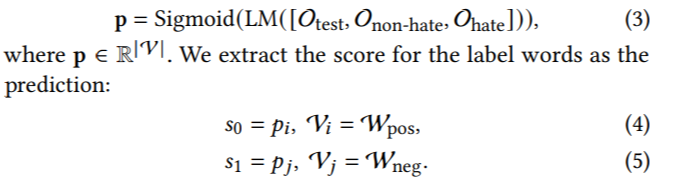
4.5 Model Training and Prediction

This paper is available on arxiv under CC 4.0 license.