
Authors:
(1) Rui Cao, Singapore Management University;
(2) Ming Shan Hee, Singapore University of Design and Technology;
(3) Adriel Kuek, DSO National Laboratories;
(4) Wen-Haw Chong, Singapore Management University;
(5) Roy Ka-Wei Lee, Singapore University of Design and Technology
(6) Jing Jiang, Singapore Management University.
Table of Links
5 EXPERIMENT
In this section, we first introduce our evaluation datasets, metrics and implementation details. Next, we introduce the baselines for comparison. Finally, we conduct qualitative analysis with case studies and error analysis to better understand the advantages and limitations of our method.
5.1 Experiment Settings
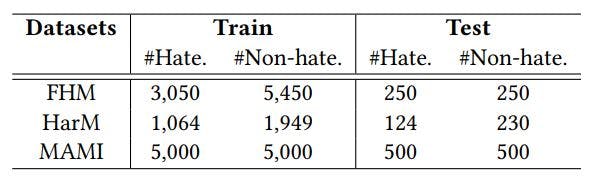
Evaluation Datasets. We test our proposed method on benchmarks for hateful meme detection. We evaluate our method on three datasets to better illustrate the generalization and stability of our approach. Table 3 presents the statistics of these datasets.
The Facebook Hateful Meme dataset (FHM) [12] was constructed by Facebook. It contains synthetic memes with added confounders such that unimodal information is insufficient for detection and deep multimodal reasoning is required. The FHM dataset contains hateful memes targeting various vulnerable groups in categories including Religion, Race, Gender, Nationality, and Disability. As the labels of the test split of FHM are not available, we performs evaluation on its dev-seen split.
Different from FHM, the Multimedia Automatic Misogyny Identification (MAMI) dataset focuses on a particular type of hateful memes, namely, those targeting women. Performance on MAMI therefore reflects the capability of hateful meme detection methods for female victims.
To test our method’s generalization capability, we also consider a harmful meme detection dataset, HarM [27]. HarM contains memes related to COVID-19, which are classified into threecategories: harmless, partially harmful, and very harmful. We merge partially harmful and harmful into one category. Because hateful content is always regarded as harmful, we use this dataset to test the capability of generalization of our proposed method from hateful meme detection to harmful meme detection.
Evaluation Metrics. Hateful meme detection is a binary classification task. In addition to detection accuracy, we also compute the Area Under the Receiver Operating Characteristics curve (AUCROC) used in prior work [2, 14, 20, 37]. We conduct experiments with ten random seeds and report the average performance and standard deviation. All models use the same set of random seeds.
Implementation Details. Given a meme image, we first detect the meme text with the open-source Easy-OCR tool [3] and then in-paint over the detected texts. To generate the answers to VQA questions, we prompt BLIP-2 [15], specifically the FlanT5XL version. We then insert the generated image captions into two text-based hateful meme detection models, i.e., the BERT-based model and the PromptHate model. For the BERT-based model, to avoid overfitting, we add a dropout rate of 0.4 to the classification layer. We use a learning rate of 2𝑒 − 5 and a batch size of 64. For PromptHate, we train the model with a batch size of 16 and empirically set the learning rate to 1.3𝑒 −5 on FHM and 1𝑒 −5 on the other two datasets [6]. We optimize both models with the AdamW optimizer [22] and implement them in PyTorch. Due to space limit, we provide more details (i.e., computation costs and model sizes) in Appendix A.
5.2 Baselines
We compare our method against both unimodal and multimodal models to demonstrate the effectiveness of the proposed method, where we regard models receiving information from one modality (i.e., the meme text or the meme image only) as unimodal models. Note that because Pro-Cap already contains image information, even if Pro-Cap is input into a unimodal BERT, the model is not considered to be unimodal.
For the unimodal models, we consider a text-only and an imageonly model. For the text-only model, we fine-tune a pre-trained BERT model [4] based on the meme text only for meme classification, which we represent as Text-BERT. For the image-only model, we first extract object-level image features with an off-the-shelf feature extractor, Faster-RCNN [30], which is trained for object detection. We then perform average pooling over object features and feed the resulting vector into a classification layer. We use Image-Region to denote the image-only model.
For multimodal models, we categorize them into two groups: 1) fine-tuning generic multimodal models that are proposed to conduct different multimodal tasks; 2) models specifically designed for hateful meme detection. For the first type of multimodal models, we firstly consider the MMBT-Region model [11], which is a widely used multimodal baseline in hateful meem detection [2, 12, 28] and the model has not been pre-trained with multimodal data. Secondly, we consider several multimodal pre-trained models, such as VisualBERT [18] pre-trained on MS-COCO [19] (VisualBERT COCO) and ViLBERT pre-trained on Conceptual Captions [32] (ViLBERT CC). Some recently released powerful pre-trained models are also included such as the Align before Fusion model [17] (ALBEF) and the Bootstrapping Language-Image Pre-training model [16] (BLIP). For the second category of baselines which are designed for the meme detection task, we consider the models listed below. The CLIP-BERT model [28] leverages the CLIP model [29] to deal with noisy meme images, uses pre-trained BERT [4] for representing meme text, and fuses them with concatenation. The MOMENTA model [28] designed both local and global multimodal fusion mechanisms to exploit multimodal interactions for hateful meme detection. Note that the MOMENTA model is designed to leverage augmented image tags (the detected image entities). DisMultiHate [14] disentangles target information from memes as targets are essential for identifying hateful content. The PromptHate model [2] is what we discussed in Section 4.4.
5.3 Experiment Results
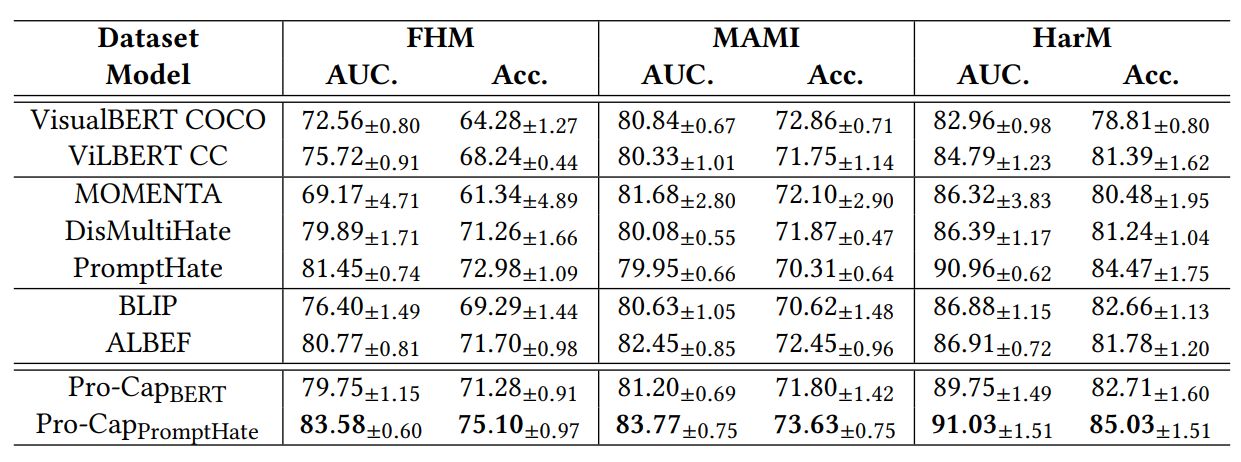
As discussed earlier, previous work has shown that additional image tags can enhance hateful meme detection. We therefore consider two settings for comparison: 1) without any augmented image tags; 2) with augmented image tags. We display the performance of models without augmented image tags in Table 4 and with augmented image tags in Table 5. The standard deviations (±) of ten random seed runs are also reported, and the best results are highlighted in bold.
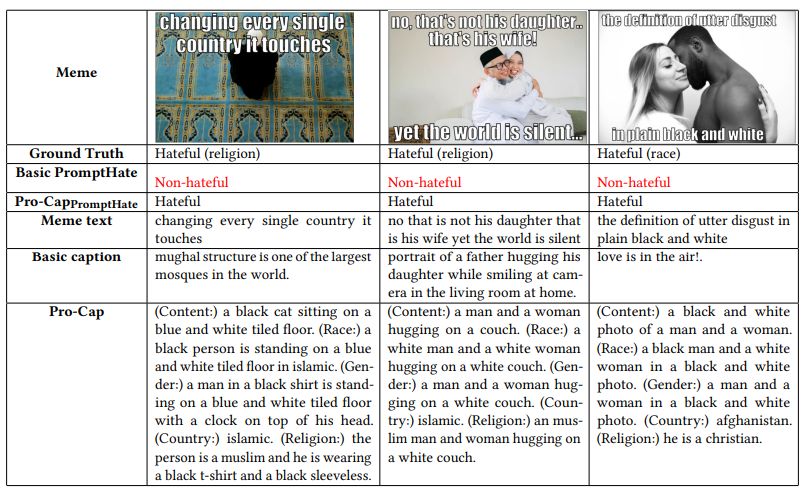
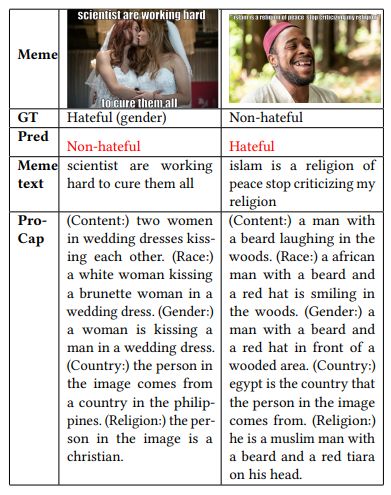
Without augmented image tags: We first compare Pro-CapBERT with unimodal and multimodal models that also utilize BERT as the text encoder (i.e., VisualBERT, ViLBERT, and MMBT-Region). Evidently, Text BERT, which utilizes only meme text, is substantially outperformed by Pro-CapBERT. This suggests that 1) visual signals are vital for hateful meme detection, and 2) the image captions obtained from the probing questions are informative.
Experiment results from multimodal pre-trained BERT-based models are presented in the second block of Table 4. Interestingly, Pro-CapBERT still has better performances in all three datasets, surpassing the most powerful multimodal pre-trained BERT-base model, ViLBERT, by over 4% on FHM and surpassing MMBT-Region by about 3% on HarM. This is despite the fact that BERT has less model parameters compared with these multimodal models (e.g, ViLBERT has 252.1M parameters while BERT only has about 110M parameters). Pro-CapBERT is still competitive against models specifically designed for hateful meme detection (i.e., models in the third block of Table 4). We provide experimental results of recently published multimodal pre-trained models (i.e., BLIP and ALBEF) in the fourth block. By comparing the simple Pro-CapBERT with these models, we observe that Pro-CapBERT gives comparable results.
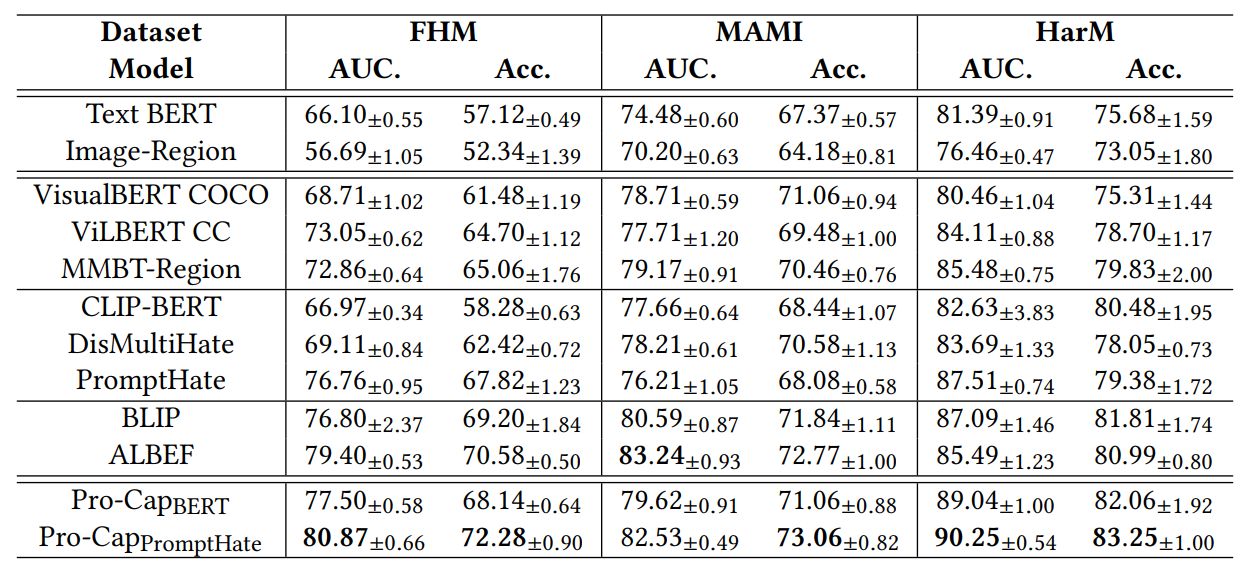
While Pro-CapBERT does not out-perform ALBEF and BLIP all the time, performance is reasonably good given that in terms of trainable parameters, Pro-CapBERT is three times smaller than these two pre-trained models. Meanwhile, Pro-CapBERT shows even better results than the two models on HarM. Notably, HarM is a realworld dataset which is much noisier than FHM. HarM also focuses on a relatively new topic (COVID-19), which may not have been observed a lot by the two pre-trained models.
When comparing BLIP and ALBEF with PromptHate, which has a similar model size, PromptHate with Pro-Cap demonstrates significant advantages over the two models on three benchmarks, especially on the noisy HarM dataset. We conjecture that a possible reason is that multimodal pre-trained models leverage pre-training data that is relatively cleaner, on a smaller scale and primarily comprises of non-memes. This leads to some difficulties when confronted with noisy real-world memes. In contrast pure language models are pre-trained on larger and noisier data, which may lead to some intrinsic robustness. If visual signals are reasonably converted to text, pure textual models can be competitive for multimodal tasks such as hateful meme detection.
Reinforcing the point of proper visual signal conversion, the enhanced performance of Pro-CapPromptHate over PromptHate highlights the importance of our probing-based captioning method, which provides essential cues for hateful content detection. With probe-based captioning, Pro-CapPromptHate is able to conduct deep multimodal reasoning that require background knowledge (due to the good performance on FHM), is stable towards noisy real-world meme data (according to performance on HarM), and has great generalization in meme detection (according to the good performance on all three benchmarks).
With augmented image tags: For a fair comparison with recent state-of-the-art models, we consider testing our proposed probecaptioning method with the same set of augmented image tags from baselines. To utilize the augmented image tags, we simply pad these tags at the end of each textual meme representation in a similar manner to [2]. With additional image information such as entities and demographic information, most models have some improvements. An interesting thing is that neither BLIP nor ALBEF benefits much from additional image tags. This is because the additional tags are usually single words or short phrases, which may be noisy or redundant, while BLIP and ALBEF may be less capable of dealing with noisy inputs. Similar to the results in Table 4, when augmenting image information: 1) the simple Pro-CapBERT still obviously surpasses multimodal pre-trained BERT-base models such as VisualBERT or ViLBERT; 2) the Pro-CapBERT performs better than models with similar sizes but specifically designed for hateful meme detection (i.e., MOMENTA or DisMultiHate) in most cases; 3) the Pro-CapBERT achieves comparable results compared with more powerful multimodal pre-trained models, which is about three times larger and surpasses them on the HarM dataset, which is real-world and noisy; 4) Pro-CapPromptHate surpasses the original PromptHate and achieves the best performance on three benchmarks as well. An interesting point is that comparing Pro-CapPromptHate without any augmented tags and original PromptHate with augmented additional image information, they achieve comparable performance on FHM and HarM and the former even surpasses the latter on MAMI. However, extracting the additional image information is expensive and laborious, which can be replaced by probing-based captioning according to the experimental results. The equally good performance on three benchmarks highlights the stability and generalization of our proposed approach.
5.4 Ablation Study
In this section, we conduct ablation studies to better understand our Pro-Cap method. Specifically, we consider the impact of asking different questions and the impact of the length of answers to the probing questions. To eliminate other factors, we consider ProCapPromptHate without any augmented image tags. For brevity, we only show accuracy in this section. We present the full results in Appendix B.
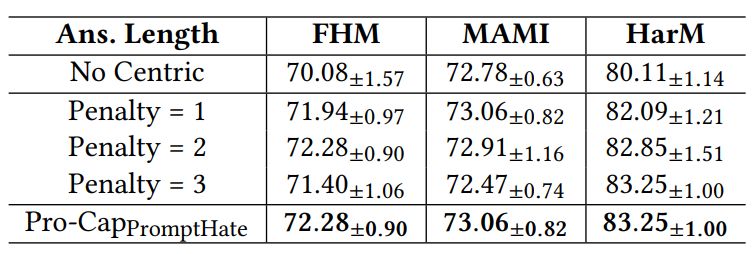
The impact of asking hateful-content centric questions: We first conduct an ablation study on the effect of prompting PVLMs with questions facilitating hateful meme detection. According to Table 2, the first question asks about the image content while all questions in the second block are for common vulnerable targets of hateful contents. To better understand the impact of including image captions generated by these target-specific questions, we experiment with a setting where captions from the target-specific questions are removed and only the generic caption about image content is used. The results are shown in the first block of Table 6. Compared with the last block of the table, we observe that with captions generated by target-specific probing questions, the model’s performance improved on all three datasets, specifically with over 2% on FHM and over 3% on HarM. However, we notice minor improvement on MAMI. We believe that this is because MAMI memes are all related to woman and generic captions about meme images may already cover the gender of persons in the image. However, the other two datasets involve memes with more complexities and therefore asking a wide ragen of target-specific probing questions is more helpful. It also implies that in real-world hateful meme detection, probing-based captioning would be helpful.
The length of answers to probing questions: We apply BLIP-2 as a zero-shot VQA model. Different from existing VQA benchmarks [7, 10], where answers are often single words or short phrases, we may want the answers used as image captions to be longer and thus more informative. In this cases, we experiment with answers of different length. To conduct the analysis, we set the length penalty in BLIP-2’s text decoder for answer generation with different values (i.e., 1, 2 and 3). With increased length penalty, longer answers are encouraged. We show results of model performance with different answer length in Table 6. The results show that detection performance is robust and does not vary much with different answer lengths. This indicates the stability of the Pro-Cap method. On the other hand, to a very small extent, different datasets do favor answers of different lengths. For instance, the HarM dataset prefers longer answers while the MAMI dataset prefers shorter answers.
[3] https://github.com/JaidedAI/EasyOCR
This paper is available on arxiv under CC 4.0 license.