
This paper is available on arxiv under CC 4.0 license.
Authors:
(1) Rui Cao, Singapore Management University;
(2) Ming Shan Hee, Singapore University of Design and Technology;
(3) Adriel Kuek, DSO National Laboratories;
(4) Wen-Haw Chong, Singapore Management University;
(5) Roy Ka-Wei Lee, Singapore University of Design and Technology
(6) Jing Jiang, Singapore Management University.
Table of Links
APPENDIX
A DETAILS FOR IMPLEMENTATION
We implement all models under the PyTorch Library with the CUDA11.2 version. We use the Tesla V 100 GPU, each with a dedicated memory of 32GB. For models specifically implemented for hateful meme detection, we take the codes published from the author for reimplementation [4]. For pre trained models which can be found under the Huggingface Library, we use the packages from Huggingface [5], specifically the BERT [4], VisualBERT [18] and the BLIP model. Gor ViLBERT [23], we take the released code from the authors [6]. For ALBEF [17] and BLIP-2 [15], we use the packages under the LAVIS Library [7]
For each meme image, we constrain the total length of the meme text and the generic image caption (either from the captioning model or by asking about the content of the image) to be 65. For each additional questions, we restrict its length to be shorter than 20. If the concatenation of the sentence exceeds the limited length, the sentence will be truncated, otherwise, if the sentence is shorted than the limited length, it will be padded. We set the number of training epochs to be 10 for all models.
The number of model parameters are summarized in Table 11.
B FULL ABLATION STUDY RESULTS
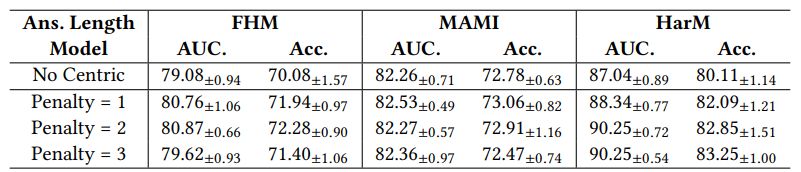
Due to the limitation of space, we only show results of accuracy in ablation studies in Table 6. The full results including both the AUC and the accuracy are provided in Table 12.
C VISUALIZATION CASES
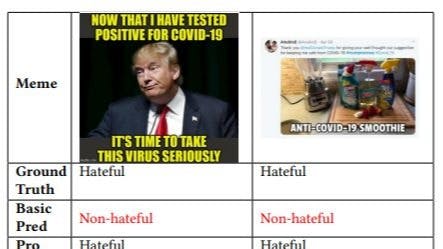
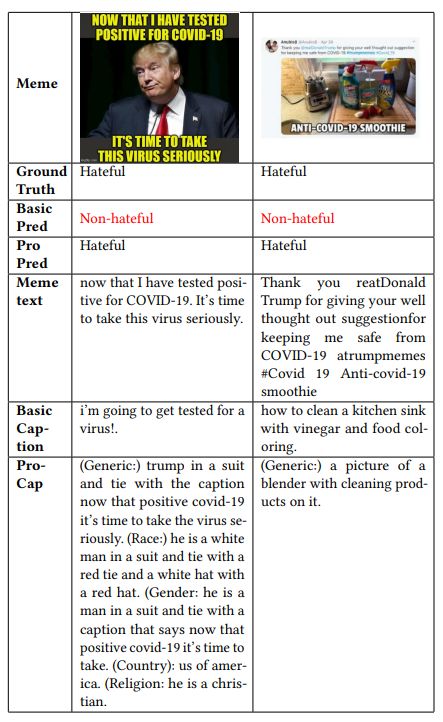
In Section 5.5, we provide visualization of cases for comparing ProCapPromptHate with the basic PromptHate. Due to space constraints, we omit examples from the other two datasets. We provide more visualization cases in this part. The cases from the HarM dataset are illustrated in Table 9 and the cases from the MAMI dataset are shown in Table 10.
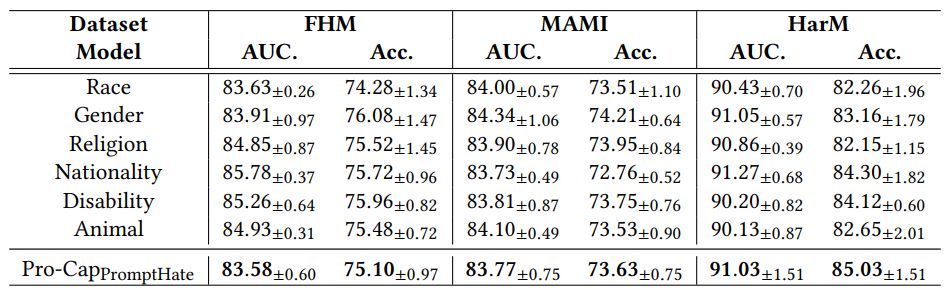
D RESULTS WITH PRO-CAP ABOUT ONE TARGET
In Section 5, we only report results when models use Pro-Cap from all probing questions. In this part, we report results (with entities) when using the answers from a single probing question in Table 13.
According to the results, we observe models using answers to a single probing question are all powerful and some even surpass heuristically asking all probing questions (e.g., using the question asking about nationality on FHM is better than using all probing questions). It points out using all probing captions may not be the optimal solution and may generate irrelevant image descriptions. For instance, confronted with a hateful meme targeting at black people, it is meaningless to ask the religion of people in the image. Interestingly, on MAMI, when only using answers to the probing question about gender reaches teh best performance. It is because MAMI contains only hateful memes about woman. A promising direction would train the model to dynamically select probing questions essential for meme detection for different memes.
[4] CLIP-BERT/MOMENTA: https://github.com/LCS2-IIITD/MOMENTA;DisMultiHate: https://gitlab.com/bottle_shop/safe/dismultihate; PromptHate: https://gitlab.com/bottle_shop/safe/prompthate
[5] https://huggingface.co/
[6] https://github.com/facebookresearch/vilbert-multi-task
[7] https://github.com/salesforce/LAVIS heuristically asking all probing questions (e.g., usin