
Authors:
(1) Rui Cao, Singapore Management University;
(2) Ming Shan Hee, Singapore University of Design and Technology;
(3) Adriel Kuek, DSO National Laboratories;
(4) Wen-Haw Chong, Singapore Management University;
(5) Roy Ka-Wei Lee, Singapore University of Design and Technology
(6) Jing Jiang, Singapore Management University.
Table of Links
ABSTRACT
Hateful meme detection is a challenging multimodal task that requires comprehension of both vision and language, as well as cross-modal interactions. Recent studies have tried to fine-tune pre-trained vision-language models (PVLMs) for this task. However, with increasing model sizes, it becomes important to leverage powerful PVLMs more efficiently, rather than simply fine-tuning them. Recently, researchers have attempted to convert meme images into textual captions and prompt language models for predictions. This approach has shown good performance but suffers from noninformative image captions. Considering the two factors mentioned above, we propose a probing-based captioning approach to leverage PVLMs in a zero-shot visual question answering (VQA) manner. Specifically, we prompt a frozen PVLM by asking hateful contentrelated questions and use the answers as image captions (which we call Pro-Cap), so that the captions contain information critical for hateful content detection. The good performance of models with Pro-Cap on three benchmarks validates the effectiveness and generalization of the proposed method.[1]
CCS CONCEPTS
• Computing methodologies → Natural language processing; Computer vision representations.
KEYWORDS
memes, multimodal, semantic extraction
ACM Reference Format:
Rui Cao, Ming Shan Hee, Adriel Kuek, Wen-Haw Chong, Roy Ka-Wei Lee, and Jing Jiang. 2023. Pro Cap: Leveraging a Frozen Vision-Language Model for Hateful Meme Detection. In Proceedings of the 31st ACM International Conference on Multimedia (MM ’23), October 29-November 3, 2023, Ottawa, ON, Canada. ACM, New York, NY, USA, 11 pages. https://doi.org/10.1145/3581783.3612498
Disclaimer: This paper contains violence and discriminatory content that may be disturbing to some readers.
1 INTRODUCTION
Memes, which combine images with short texts, are a popular form of communication in online social media. Internet memes are often intended to express humor or satire. However, they are increasingly being exploited to spread hateful content across online platforms. Hateful memes attack individuals or communities based on their identities such as race, gender, or religion [5, 8, 12, 27]. The propagation of hateful memes can lead to discord online and may potentially result in hate crimes. Therefore, it is urgent to develop accurate hateful meme detection methods.
The task of hateful meme detection is challenging due to the multimodal nature of memes. Detection involves not only comprehending both the images and the texts but also understanding how these two modalities interact. Previous work [14, 28, 35, 36] learns cross-modal interactions from scratch using hateful meme detection datasets. However, it may be difficult for models to learn complicated multimodal interactions with the limited amount of data available from these datasets. With the development of Pretrained Vision-Language Models (PVLMs) such as VisualBERT [18] and ViLBERT [23], recent work leverage these powerful PVLMs to facilitate the hateful meme detection task. A common approach is to fine-tune PVLMs with task-specific data [9, 20, 26, 34, 37]. However, it is less feasible to fine-tune the larger models such as BLIP-2 [15] and Flamingo [1] on meme detection because there are billions of trainable parameters. Therefore, computationally feasible solutions other than direct fine-tuning are needed to leverage large PVLMs in facilitating hateful meme detection.
![Table 1: Impact on detection performances on the FHM dataset [12] from image captions. (w/o) denotes models without additional entity and demographic information.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-yy93pe6.jpeg)
Different from the approach above using PVLMs, PromptHate[2] is a recently proposed model that converts the multimodal meme detection task into a unimodal masked language modeling task. It first generates meme image captions with an off-the-shelf image caption generator, ClipCap [25]. By converting all input information into text, it can prompt a pre-trained language model along with two demonstrative examples to predict whether or not the input is hateful by leveraging the rich background knowledge in the language model. Although PromptHate achieves state-of-the-art performance, it is significantly affected by the quality of image captions, as shown in Table 1. Image captions that are merely generic descriptions of images may omit crucial details [14, 37], such as the race and gender of people, which are essential for hateful content detection. But with additional image tags, such as entities found in the images and demographic information about the people in the images, the same model can be significantly improved, as shown in Table 1. However, generating these additional image tags is laborious and costly. For instance, entity extraction is usually conducted with the Google Vision Web Entity Detection API [2], which is a paid service. Ideally, we would like to find a more affordable way to obtain entity and demographic information from the images that is critical for hateful content detection.
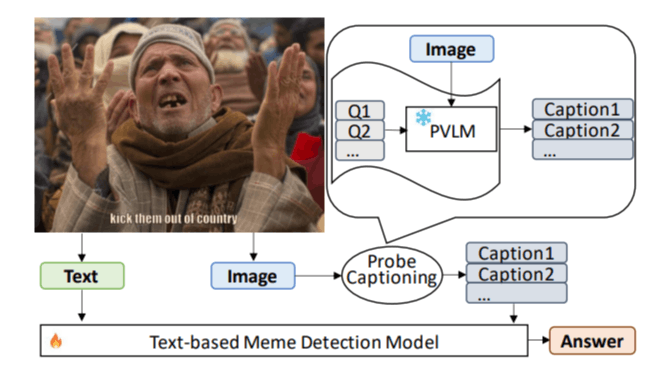
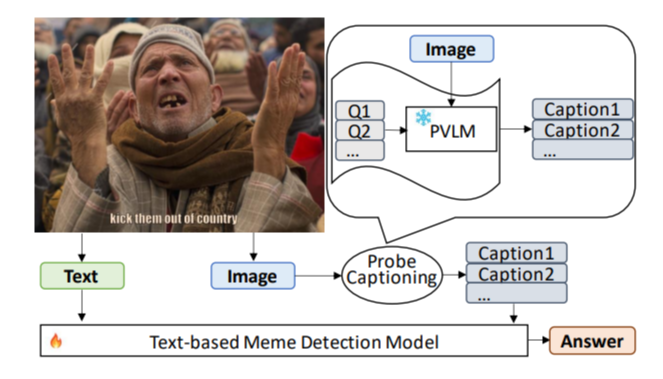
Both above-mentioned approaches (i.e., one using PVLMs and the other converting the task to a unimodal task) have their pros and cons. In this paper, we combine the ideas from these two approaches and design a hateful meme detection method that leverages the power of a frozen PVLM to complement the unimodal approach of PromptHate. Specifically, we use a set of “probing” questions to query a PVLM (BLIP-2 [15] in our experiments) for information related to common vulnerable targets in hateful content. The answers obtained from the probing questions will be treated as image captions (denoted as Pro-Cap) and used as input to a trainable hateful meme detection model. Figure 1 illustrates the overall workflow of the method. We refer to the step of using probing questions to generate the captions as probing-based captioning.
Our proposed method fills existing research gaps by: 1) Leverage a PVLM without any adaptation or fine-tuning, thereby reducing computational cost; 2) Instead of explicitly obtaining additional image tags with costly APIs, we utilize the frozen PVLM to generate captions that contain information useful for hateful meme detection. To the best of our knowledge, this is the first work that to leverage PVLMs in a zero-shot manner through question answering to assist in the hateful meme detection task. To further validate our method, we test the effect of the generated Pro-Cap on both PromptHate[2] and a BERT-based[4] hateful meme detection model.
Based on the experimental results, we observe that PromptHate with Pro-Cap (denoted as Pro-CapPromptHate) significantly surpasses the original PromptHate without additional image tags (i.e., about 4, 6, and 3 percentage points of absolute performance improvement on FHM [12], MAMI [5], and HarM [28] respectively). ProCapPromptHate also achieves comparable results with PromptHate with additional image tags, indicating that probing-based captioning can be a more affordable way of obtaining image entities or demographic information. Case studies further show that Pro-Cap offers essential image details for hateful content detection, enhancing the explainability of models to some extent. Meanwhile, ProCapBERT clearly surpasses multimodal BERT-based models of similar sizes (i.e., about 7 percentage points of absolute improvement with VisualBERT on FHM [12]), proving the generalization of the probing-based captioning method.
[1] Code is available at: https://github.com/Social-AI-Studio/Pro-Cap
[2] https://cloud.google.com/vision/docs/detecting-web
This paper is available on arxiv under CC 4.0 license.