
Authors:
(1) Vasiliki Kougia, University of Vienna, Faculty of computer science, Vienna, Austria & UniVie Doctoral School Computer Science, Vienna, Austria;
(2) Simon Fetze, University of Vienna, Faculty of computer science, Vienna, Austria;
(3) Thomas Kirchmair, University of Vienna, Faculty of computer science, Vienna, Austria;
(4) Erion Çano, University of Vienna, Faculty of computer science, Vienna, Austria;
(5) Sina Moayed Baharlou, Boston University, Department of Electrical and Computer Engineering, Boston, MA, USA;
(6) Sahand Sharifzadeh, Ludwig Maximilians University of Munich, Faculty of Computer Science, Munich, Germany;
(7) Benjamin Roth, University of Vienna, Faculty of computer science, Vienna, Austria.
Table of Links
Conclusion, Acknowledgments, and References
5 Analysis
5.1 Human augmentation
Since the MemeGraphs augmentation is produced automatically it can potentially result in inaccuracies that can deteriorate the performance of the classification models. In order to examine this scenario and also the scene graphs themselves, which were produced by an off-the-shelf model, we performed human augmentation. The augmentation was conducted by two male students, who were doing a Master of Arts (M.A.) in Digital Humanities and the process lasted about 10 weeks. Several discussions took place before the augmentation started for the evaluators to get familiar with this study and understand its scope. They also carefully studied the guidelines before and during the process.
The goal of the human augmentation was to correct the automatically generated scene graphs and add background knowledge by linking the detected objects to a knowledge base (see Fig. 1). For each detected object or relation, the first step for the evaluators was to evaluate if it is correct or not and in case of an incorrect object to correct it. The second step was to link each object to its entry in Wikidata. For example, the detected object “man” was linked to the entry for “man”. The objects represent generic types, e.g., “man”, “woman” etc., but in some cases, a specific instance of the object type might be shown, which we call entity, e.g., the woman depicted is Hillary Clinton (as shown in Fig. 1). Then, the evaluators searched for the entry of each detected object and its entity (if existing) in Wikidata and added the corresponding links. The evaluators worked towards achieving high precision and in order to limit the scope of the augmentation, no new objects or relations were added.
After a first round of augmenting a small sub-sample (around 10%), preliminary guidelines were created. These guidelines described the process mentioned in the previous paragraph in simple and brief steps. A few systematic difficulties for the Schemata algorithm were encountered in this first round that can be summarized as follows:
• The text of the meme appearing on the image was often detected as a “sign” and some parts of the text as “letter”. However, this text is not actually a sign and is not part of the image.
• In some cases, the same object was detected multiple times.
• Some memes in the dataset were screenshots of text, so there was not any useful visual information extracted
from them.
• In a few cases, there was a specific entity depicted in the meme, but the corresponding object type was not detected.
The above-mentioned difficulties were discussed with the evaluators and the guidelines were revised to include clear instructions for those cases. Based on that and other observations of the evaluators about the data, the following final guidelines were defined:
• Meme text or sign. A distinction between a meme’s text and an actual sign in the image, e.g., a sticker or a banner with text, was made. Detected objects that were referring to the meme text were discarded.
• Multiple object detection. In cases where the same object type appeared multiple times, the annotators would inspect the bounding boxes in the images to verify whether it is the same object. If yes, then only one occurrence was kept.
• Screenshots. Memes that are screenshots of text and do not contain visual information were disregarded from the augmentation process.
• Missed objects. The human augmentation is based on the automatically generated scene graphs and thus, no new objects or their corresponding entities were added.
• Bounding boxes. The bounding boxes that were drawn on the image during the automatic augmentation are not used in our study, hence they were not changed in the human augmentation.
• Incorrect objects. For each detected object, the evaluators determined if its type was correct or not. If not, then the correct type for this object was indicated, when it was possible. In cases where the object did not exist in the image at all, it was simply removed.
• Relation correction. For each relation, the evaluators determined if it was correct or not. If the type of objects that the relation referred to was incorrect, then, the type was replaced with the correct one. Following the same approach as with the objects, no new relations were added neither was an object that was not detected added to a relation.
• Knowledge base. Each object was mapped to a specific entity when possible by adding a link to Wikidata.
After the guidelines were finalized, the entire dataset was augmented. The inter-annotator agreement and Cohen’s kappa regarding the correctness of the detected objects were 83.84% and 0.60 respectively, while for the correctness of the detected relations it was 78.05% and 0.53. The first evaluator found that 12.95% of the automatically detected objects needed correction. The second evaluator found a larger percentage of incorrect objects around 21.86%. Similar outcomes were observed for the relations, where the first evaluator found 22.13% of the relations to be incorrect, while the second found 31.48%. The number of objects found incorrect by both evaluators was 1,127 and for these cases, they agreed on the correct object 282 times. This low agreement shows that deciding about the exact type of objects shown in an image is a difficult task. The relations found incorrect by both evaluators were 1,820. Regarding the knowledge base linking, more inconsistencies were found and the evaluators added the same link in 4,314 out of 9,666 cases. In Fig. 4, we see examples of cases that caused the low agreement. Sub-figures (a) and (b) contain detected objects that both evaluators agreed are incorrect (e.g., “10-tree” in (a) and “13-wheel” in (b)). However, they did not add the same correct object. For example, the object “13 wheel” in (b), was corrected as “shoe” by one evaluator and as “foot” by the other.
Both of these corrections can be considered valid. Regarding adding the links to Wikidata, similar uncertainties can be found. In cases of disagreement, we chose the correct object or link for the final dataset by the following heuristic: for each annotated alternative, we counted its occurrence in the part of the dataset that had 100% agreement, i.e., the more frequent object or link was finally chosen. For the entity links, there are cases that the evaluators added a different link, but both of the links were correct. In sub-figure (c), we see such a case in which “0-face” depicts both “Bernie Sanders” and “Yoda”. Hence, both links were added to the final augmentations. In cases where the evaluators disagreed regarding the correctness of an object or relation, they were removed.
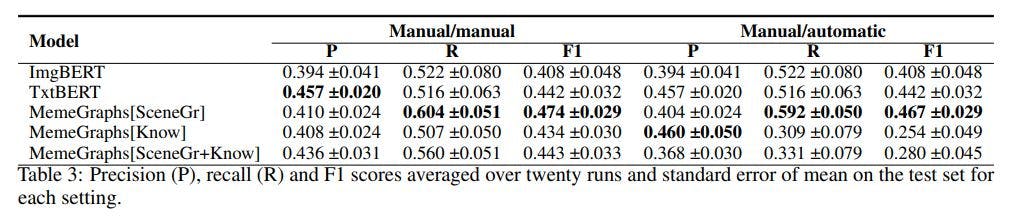
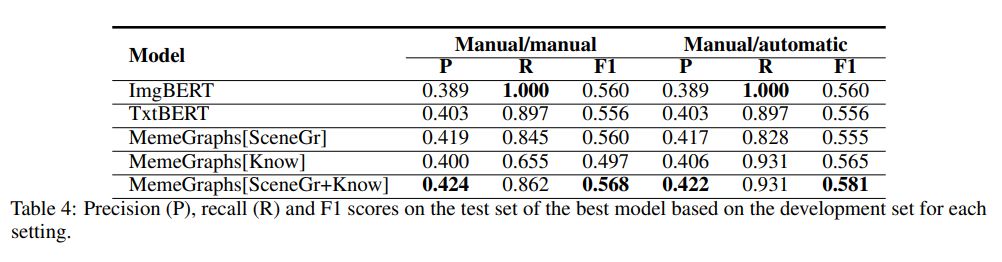
To conclude our analysis based on human augmentation, we used the results of the aforementioned process as inputs to the models described in Section 4.1. We experimented with two different settings for training and testing the models. First, we used the results of the manual augmentation, which are the corrected scene graphs and manually linked knowledge, both for training and inference (manual/manual). Second, we combined the two augmentations and trained on the manual ones, and tested on the automatic ones (manual/automatic). In this case, the automatic augmentations are the scene graphs corrected automatically based on the manual corrections of the training data. We kept in the development and test scene graphs only the objects that were manually marked as correct at least once in the training scene graphs and removed the rest (i.e., the ones that the evaluators found were always falsely detected by the scene graph model). The knowledge base information consisted of the descriptions of the automatically detected text entities (See Subsection 3.2). We used the same experimental setup as for the MemeGraphs method described in Subsection 4.2. The average results over the 20 runs are shown in Table 3 and the score of the models performing best on the development set in Table 4. We observe that in both settings MemeGraphs[SceneGr+Know] achieves the best F1 score in Table 4, similar to the fully automatic setting (Table 2). On the other hand, when looking at the average, the TxtBERT with only the scene graphs as input obtains the best score (MemeGraphs[SceneGr])in both the manual/manual and the manual/automatic settings.
5.2 Discussion
We observe that overall our proposed method outperforms its competitors in terms of F1 score in all settings (fully automatic, manual/manual, manual/automatic). Between the different settings, we see that the models with the fully automatic setting have the best scores (MemeGraphs[Know] in Table 1 and MemeGraphs[SceneGr+Know] in Table 2), even though manual augmentations would be expected to be more accurate than the automatic ones. Furthermore, not only the best score is achieved by the MemeGraphs[Know] model in the fully automatic setting, but this model’s performance is improved in this setting compared to the manual ones. The scene graphs infused model also achieves better results in the fully automatic setting, showing that the automatically produced scene graphs are accurate enough and no manual correction is needed. In the manual/automatic setting, all the models performed worse compared to the other settings. This fact shows that models trained on manual annotations are not able to generalize in the automatic setting. This holds true especially in the MemeGraphs[Know] model, since in the automatic setting no information for the type of the objects exists in the input. To gain insights into that behavior, we analyze the different challenges that were faced in the manual and the automatic augmentation and compare their results.
During the manual augmentation, both correcting the scene graphs and adding background knowledge were found challenging. Regarding the scene graphs, memes contain complex information and images, which made the correction of objects difficult for the evaluators (see Subsection 5.1). Background knowledge for specific entities was also difficult to add for three main reasons: 1. the evaluators may not know the person depicted in the image, 2. many memes were screenshots of posts, so there was no actual visual information, and 3. meme texts often refer to entities that are not shown in the image. This resulted in detecting entities for only 409 memes out of 743. The automatic entity detection, on the other hand, was based on the text, which assisted in overcoming the three aforementioned challenges and extracted entities for all the memes.
Regarding the automatic augmentation based on the entities detected by the NER model, the main challenge consists of linking the detected entities to the knowledge base. Even though the model managed to extract entities from all the texts showing that we can obtain rich information, linking them to the knowledge base was not easy. Many times the entities appear in the text with only their first name, e.g., “Hillary”, or their first and last name concatenated, e.g., “donaldtrump”, or are detected alongside some other word, e.g., “green Bernie”. When these entities are searched for in the knowledge base, the results might not be accurate and contain data entries for many entities from which we choose the first as the most related one. However, this can lead to adding a link to the wrong entity.
This paper is available on arxiv under CC 4.0 license.