
Authors:
(1) Vasiliki Kougia, University of Vienna, Faculty of computer science, Vienna, Austria & UniVie Doctoral School Computer Science, Vienna, Austria;
(2) Simon Fetze, University of Vienna, Faculty of computer science, Vienna, Austria;
(3) Thomas Kirchmair, University of Vienna, Faculty of computer science, Vienna, Austria;
(4) Erion Çano, University of Vienna, Faculty of computer science, Vienna, Austria;
(5) Sina Moayed Baharlou, Boston University, Department of Electrical and Computer Engineering, Boston, MA, USA;
(6) Sahand Sharifzadeh, Ludwig Maximilians University of Munich, Faculty of Computer Science, Munich, Germany;
(7) Benjamin Roth, University of Vienna, Faculty of computer science, Vienna, Austria.
Table of Links
Conclusion, Acknowledgments, and References
ABSTRACT
Memes are a popular form of communicating trends and ideas in social media and on the internet in general, combining the modalities of images and text. They can express humor and sarcasm but can also have offensive content. Analyzing and classifying memes automatically is challenging since their interpretation relies on the understanding of visual elements, language, and background knowledge. Thus, it is important to meaningfully represent these sources and the interaction between them in order to classify a meme as a whole. In this work, we propose to use scene graphs, that express images in terms of objects and their visual relations, and knowledge graphs as structured representations for meme classification with a Transformer-based architecture. We compare our approach with ImgBERT, a multimodal model that uses only learned (instead of structured) representations of the meme, and observe consistent improvements. We further provide a dataset with human graph annotations that we compare to automatically generated graphs and entity linking. Analysis shows that automatic methods link more entities than human annotators and that automatically generated graphs are better suited for hatefulness classification in memes.
Keywords hate speech · internet memes · knowledge graphs · multimodal representations.
1 Introduction
Internet memes are items such as images, videos, or twitter posts that are widely shared on social media and typically relate to several subjects, such as politics, social, news, and current internet trends.[1] Memes are a popular form of communication and they are often used as a means to express an opinion or stance in a humorous or sarcastic manner, but they can also be hateful and promote problematic content that is likely to hurt specific groups of people and hence be harmful to society in general [2]. Thus, analyzing trending memes can provide insight into people’s reactions and opinions to important societal matters, as well as to the traits of different groups. This can help in tasks like filtering out harmful memes from internet platforms or extracting user opinions for socioeconomic studies. This work focuses on memes in the form of images with some form of superimposed text (sometimes referred to with the technical term image macros) with the goal of detecting hateful content.
Lately, there has been increased interest in deep learning models for analyzing memes and classifying them [23, 10, 11], for example in the context of the Hateful Memes competition organized by Facebook [13] and the shared task in the Workshop on Online Abuse and Harms (WOAH) 2021 that was the continuation of the first competition [21]. Another shared task in Semeval 2022 aimed at detecting misogyny in memes [11]. Alongside these shared tasks, the corresponding datasets were published with human annotations capturing important properties such as hatefulness and misogyny. Recent works use multimodal representation learning based on image features from Convolutional Neural Networks (CNNs), Transformer-based language models for the text [13, 3, 14] or multimodal (vision+language) Transformer models in order to classify memes [13]. Some works additionally incorporate specifically extracted image features such as race [33], person attributes [1, 23], and automatic image captioning output [7, 4]. However, none of these works have included the relations between objects in the form of scene graphs or background knowledge in the form of a text description for the objects depicted in the image.
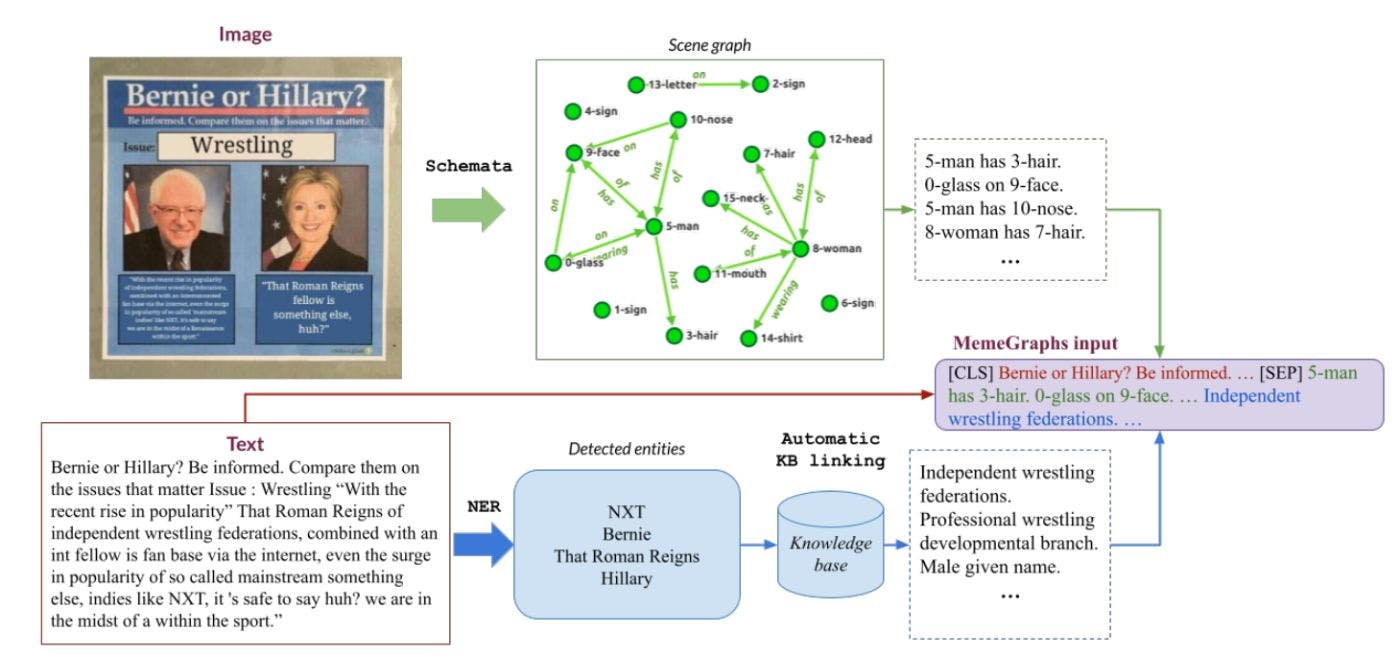
![Figure 1: The steps performed by the MemeGraphs method. The automatic augmentation consists of scene graphs generated automatically by a pre-trained model (Schemata [26]) and entities detected in the text by a pre-trained Named Entity Recognition (NER) model. Background knowledge for each entity is retrieved from a knowledge base (Wikidata). The final MemeGraphs input is created by concatenating these augmentations and adding them after the [SEP] token following the text of the meme in order to feed it to a Transformer for text classification.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-4f83v67.jpeg)
In this paper, we address the issue of classifying hateful memes by performing an automated augmentation in order to represent the visual information and background knowledge (Fig. 1). We built on the MultiOFF dataset, which contains memes extracted from social media during the 2016 U.S. Presidential Election [28]. An off-the-shelf scene graph generation model was employed to produce scene graphs, which contain detected visual objects and relations between them for each meme, and a NER model to detect entities that we linked to background knowledge. The scene graphs were serialized as text resulting in a unified way to represent all the modalities expressed in a meme. This allows using a (unimodal) text classifier to classify the multimodal memes. Hence, we incorporated the automatically produced augmentations to classify the memes using a text-based Transformer model and show that they can improve its performance. The explicit representation of the image as serialized tokens also provides a more interpretable intermediate representation (compared to hidden layers in multimodal models such as ImgBERT [13, 14]).
Furthermore, in order to examine how the results of the automatic augmentation would deviate from human ones, we performed manual augmentation. Two human evaluators corrected the automatically produced scene graphs and manually added background knowledge. We compare our automatic MemeGraphs method with models operating on the manually augmented data (only for training or for both training and inference) and find that automatic augmentations assist in achieving better results than manual ones.
Contribution Our contributions can be summarized as follows:
• We propose MemeGraphs, a novel method for classifying memes utilizing scene graphs augmented with knowledge and providing insights for processing multimodal documents.
• We show that adding this kind of knowledge to a text-based Transformer model can improve its classification performance. Furthermore, we show that this yields improvements compared to a simple model only using learned representations to classify the memes, such as ImgBERT.
• We conduct extensive experiments with manual and automatic settings for obtaining this knowledge and show that the automatic setting of our MemeGraphs method provides more meaningful information.
In the following, we discuss related work and present our MemeGraphs method. Subsequently, in Section 4, we describe the models we implemented and report their results. Finally, we provide a qualitative analysis, including a discussion of the findings of human augmentation, and compare this with the automatic MemeGraphs method.[2]
[1] Disclaimer: This paper contains examples of hateful content.
[2] The code and data for the MemeGraphs method are available on: https://github.com/vasilikikou/memegraphs.
This paper is available on arxiv under CC 4.0 license.