
Authors:
(1) Muzhaffar Hazman, University of Galway, Ireland;
(2) Susan McKeever, Technological University Dublin, Ireland;
(3) Josephine Griffith, University of Galway, Ireland.
Table of Links
Conclusion, Acknowledgments, and References
A Hyperparameters and Settings
E Contingency Table: Baseline vs. Text-STILT
Abstract
Internet Memes remain a challenging form of user-generated content for automated sentiment classification. The availability of labelled memes is a barrier to developing sentiment classifiers of multimodal memes. To address the shortage of labelled memes, we propose to supplement the training of a multimodal meme classifier with unimodal (image-only and textonly) data. In this work, we present a novel variant of supervised intermediate training that uses relatively abundant sentiment-labelled unimodal data. Our results show a statistically significant performance improvement from the incorporation of unimodal text data. Furthermore, we show that the training set of labelled memes can be reduced by 40% without reducing the performance of the downstream model.
1 Introduction
As Internet Memes (or just “memes”) become increasingly popular and commonplace across digital communities worldwide, research interest to extend natural language classification tasks, such as sentiment classification, hate speech detection, and sarcasm detection, to these multimodal units of expression has increased. However, state-of-the art multimodal meme sentiment classifiers significantly underperform contemporary text sentiment classifiers and image sentiment classifiers. Without accurate and reliable methods to identify the sentiment of multimodal memes, social media sentiment analysis methods must either ignore or inaccurately infer opinions expressed via memes. As memes continue to be a mainstay in online discourse, our
ability to infer the meaning they convey becomes increasingly pertinent (Sharma et al., 2020; Mishra et al., 2023).
Achieving similar levels of sentiment classification performance on memes as on unimodal content remains a challenge. In addition to its multimodal nature, multimodal meme classifiers must discern sentiment from culturally specific inputs that comprise brief texts, cultural references, and visual symbolism (Nissenbaum and Shifman, 2017). Although various approaches have been used to extract information from each modality (text and image) recent works have highlighted that meme classifiers must also recognise the various forms of interactions between these two modalities (Zhu, 2020; Shang et al., 2021; Hazman et al., 2023).
Current approaches to training meme classifiers are dependent on datasets of labelled memes (Kiela et al., 2020; Sharma et al., 2020; Suryawanshi et al., 2020; Patwa et al., 2022; Mishra et al., 2023) containing sufficient samples to train classifiers to extract relevant features from each modality and relevant cross-modal interactions. Relative to the complexity of the task, the current availability of labelled memes still poses a problem, as many current works call for more data (Zhu, 2020; Kiela et al., 2020; Sharma et al., 2022).
Worse still, memes are hard to label. The complexity and culture dependence of memes
(Gal et al., 2016) cause the Subjective Perception Problem (Sharma et al., 2020), where varying familiarity and emotional reaction to the contents of a meme from each annotator causes different ground-truth labels. Second, memes often contain copyright-protected visual elements taken from other popular media (Laineste and Voolaid, 2017), raising concerns when publishing datasets. This required Kiela et al. (2020) to manually reconstruct each meme in their dataset using licenced images, significantly increasing the annotation effort. Furthermore, the visual elements that comprise a given meme often emerge as a sudden trend that rapidly spreads through online communities (Bauckhage, 2011; Shifman, 2014), quickly introducing new semantically rich visual symbols into the common meme parlance, which carried little meaning before (Segev et al., 2015). Taken together, these characteristics make the labelling of memes particularly challenging and costly.
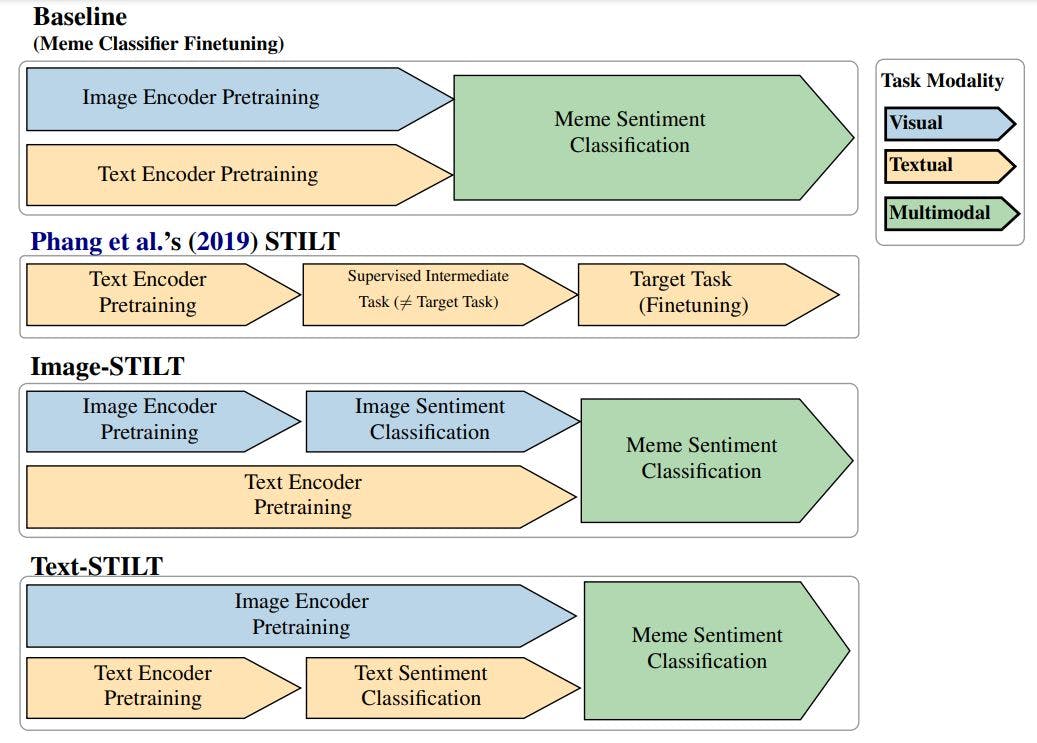
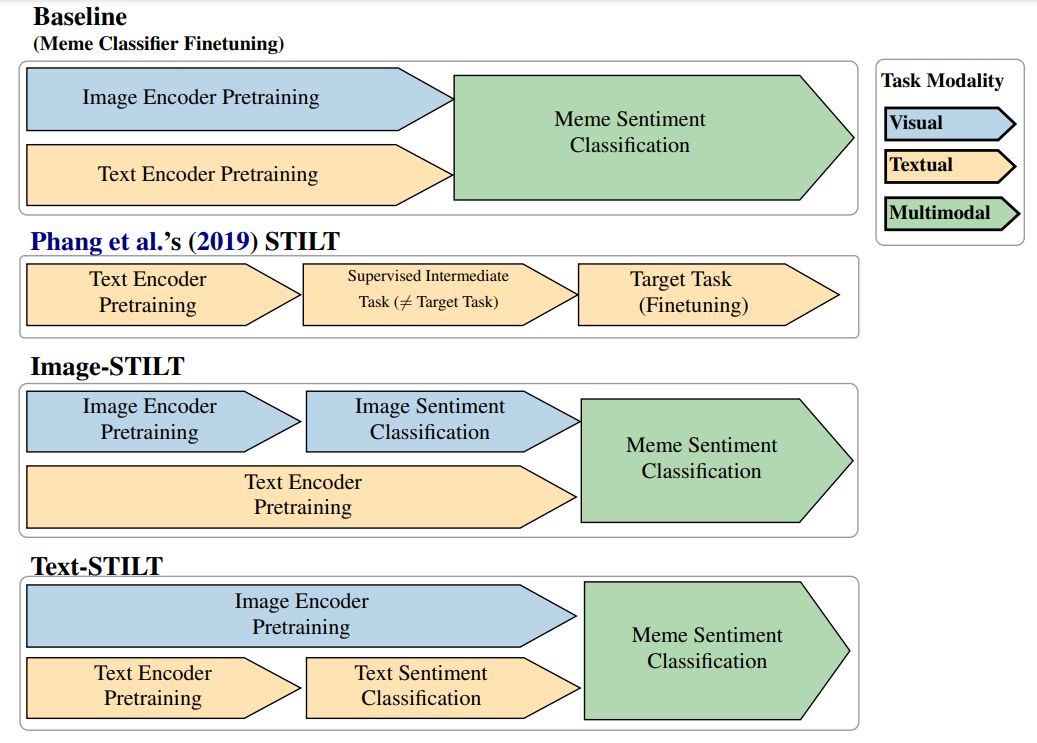
In seeking more data-efficient methods to train meme sentiment classifiers, our work attempts to leverage the relatively abundant unimodal sentiment-labelled data, i.e. sentiment analysis datasets with image-only and text-only samples. We do so using Phang et al.’s (2019) Supplementary Training on Intermediate Labeleddata Tasks (STILT) which addresses the low performance often encountered when finetuning pretrained text encoders to data-scarce Natural Language Understanding (NLU) tasks. Phang et al.’s STILT approach entails three steps:
1. Load pretrained weights into a classifier model.
2. Finetune the model on a supervised learning task for which data is easily available (the intermediate task).
3. Finetune the model on a data-scarce task (the target task) that is distinct to the intermediate task.
STILT has been shown to improve the performance of various models in a variety of text-only target tasks (Poth et al., 2021; Wang et al., 2019). Furthermore, Pruksachatkun et al. (2020) observed that STILT is particularly effective in target tasks in NLU with smaller datasets, e.g. WiC (Pilehvar and Camacho-Collados, 2019) and BoolQ (Clark et al., 2019). However, they also showed that the performance benefits of this approach are inconsistent and depend on choosing appropriate intermediate tasks for any given target task. In some cases, intermediate training was found to be detrimental to target task performance; which Pruksachatkun et al. (2020) attributed to differences between the required “syntactic and semantic skills” needed for each intermediate and target task pair. However, STILT has not yet been tested in a configuration in which intermediate and target tasks have different input modalities.
Although only considering the text or image of a meme in isolation does not convey its entire meaning (Kiela et al., 2020), we suspect that unimodal sentiment data may help incorporate skills relevant to discern the sentiment of memes. By proposing a novel variant of STILT that uses unimodal sentiment analysis data as an intermediate task in training a multimodal meme sentiment classifier, we answer the following questions:
RQ1: Does supplementing the training of a multimodal meme classifier with unimodal sentiment data significantly improve its performance?
We separately tested our proposed approach with image-only and text-only 3-class sentiment data (creating Image-STILT and Text-STILT, respectively) as illustrated in Figure 1). If either proves effective, we additionally answer:
RQ2: With unimodal STILT, to what extent can we reduce the amount of labelled memes whilst preserving the performance of a meme sentiment classifier?
This paper is available on arxiv under CC 4.0 license.