

Authors:
(1) Muzhaffar Hazman, University of Galway, Ireland;
(2) Susan McKeever, Technological University Dublin, Ireland;
(3) Josephine Griffith, University of Galway, Ireland.
Table of Links
Conclusion, Acknowledgments, and References
A Hyperparameters and Settings
E Contingency Table: Baseline vs. Text-STILT
C Architectural Details
Our models are based on the Baseline model proposed by Hazman et al. (2023) and we similarly utilise the Image and Text Encoders from the pretrained ViT–B/16 CLIP model to generate representations of each modality.
FI = ImageEncoder(Image)
FT = T extEncoder(Text)
Where each FI and FT is a 512-digit embedding of the image and text modalities, respectively, from CLIP’s embedding space that aligns images with their corresponding text captions (Radford et al., 2021).
For unimodal inputs, the encoder for the missing modality is fed a blank input, i.e. when finetuning on unimodal images, the text input is defined as a string containing no characters i.e. “”:
FI = ImageEncoder(Image)
FT = TextEncoder(“”)
Conversely, when finetuning on unimodal texts, the image input is defined as a 3 × 224 × 224 matrix of zeros, or equivalently, JPEG file with all pixels set to black.
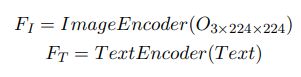



This paper is available on arxiv under CC 4.0 license.